---
name: rocksdb
title: RocksDB 架构设计与核心机制(1/2)
date: 2026-04-11
---
存储领域,RocksDB 几乎是绕不开的一个话题。TiDB 底层的 TiKV 用它做存储引擎,Flink 用它做状态后端,Kafka Streams 用它存状态数据,Facebook 的 MyRocks 拿它替代 InnoDB 支撑社交数据,很多区块链和数据库系统也会用它做本地持久化存储。从数据库到消息队列,从流计算到区块链,只要涉及到高性能的本地持久化存储,RocksDB 几乎都是首选。可以说,只要你在做和存储相关的事情,迟早会和它打交道。
网上关于 RocksDB 的文章不少,但大多只是蜻蜓点水地介绍一下 LSM-Tree,然后就结束了,很多核心机制讲得并不透彻。说实话,这种文章看完之后,读者大概率还是一脸懵:WAL 到底干了什么?MemTable 和 SST 是怎么接上的?Compaction 到底在整理什么?
所以我打算自己写一篇,从最基础的概念开始,尽量把 RocksDB 的整体架构、写入路径、读取路径、后台整理机制讲清楚。我们的目标是先把整体骨架搭起来,只要骨架搭起来了,后面不管是做技术选型、排查线上问题,还是想进一步看源码,都不会太痛苦。
如果你之前完全没接触过 RocksDB 也不要有什么压力,文章会从基础概念讲起,逐步深入。如果你已经有一定了解,可以直接跳到感兴趣的章节。了解基本的数据结构(如跳表、B+ 树),对磁盘 I/O 有基本认识就够了。
## RocksDB 是什么
简单来说,RocksDB 是一个嵌入式的、高性能的、持久化的 Key-Value 存储引擎。它由 Facebook 在 Google 的 LevelDB 基础上 fork 并优化而来,专门针对快速存储介质(如 SSD、NVMe)做了大量优化。
这里有几个关键词需要解释一下。先别急着往后看,这几个词其实挺关键:
- **嵌入式**:RocksDB 不是一个独立的数据库服务,而是以库的形式嵌入到你的应用进程中。它没有 Client-Server 架构,你直接在代码里调用它的 API 就行了。这一点和 SQLite 类似。
- **Key-Value**:数据模型很简单,就是 key-value 对,key 和 value 都是任意的字节数组。
- **持久化**:数据会落盘,重启不丢。
你可能会问:既然 LevelDB 已经有了,为什么还要搞一个 RocksDB?简单说,LevelDB 是一个非常优秀的项目,但它毕竟是一个单线程的实现,对多核 CPU 和 SSD 的利用都不够充分。Facebook 在实际生产中遇到了性能瓶颈,所以在 LevelDB 的基础上做了很多改进,比如多线程 Compaction、Column Family、各种压缩算法支持等等。
## 快速上手:RocksDB 存什么、怎么用
废话不多说,我们先来建立一个直观的认识:RocksDB 到底存什么数据?怎么操作?这个部分还是比较简单的,我们先把最表层的使用方式过一遍。
### 数据模型
RocksDB 的数据模型极其简单,简单到有点"朴素"——就是 key-value 对,key 和 value 都是字节数组(byte array)。它不像 MySQL 那样有表结构、字段类型、SQL 查询,RocksDB 只认字节。
这意味着你想存什么都行:
- 一个用户 ID → 用户的 JSON 数据
- 一个时间戳 → 一条日志记录
- 一个自定义的复合 key → 一个序列化后的对象
至于怎么把你的业务数据编码成字节数组、怎么设计 key 的格式,这些都是应用层自己决定的,RocksDB 不管。它只负责高效地存储、查询和遍历这些 key-value 对,并且保证 key 是有序存储的(按字节序排列)。
这个"有序"非常重要,非常重要,非常重要。正因为 key 是有序的,你不仅可以做精确的点查(给一个 key,取一个 value),还可以做范围扫描(比如查找所有以 "user:" 开头的 key)。很多上层系统正是利用了这个特性来实现复杂的查询能力。
### 核心操作
RocksDB 提供的 API 其实很少,核心就这么几个:
- **Put(key, value)**:写入一个 key-value 对,如果 key 已存在就覆盖
- **Get(key)**:根据 key 查询 value
- **Delete(key)**:删除一个 key
- **Iterator**:创建一个迭代器,用来范围扫描
- **WriteBatch**:把多个写操作打包成一个原子操作
简单吧?就这些。没有 JOIN,没有 GROUP BY,没有索引,什么都没有。RocksDB 就是一个纯粹的 key-value 存储,简单到不能再简单了。
不过大家不要因为 API 少,就小看这个东西。很多复杂的分布式数据库,底层用的就是这么几个非常朴素的接口。上层看起来很花哨,底层往往就是 `Put/Get/Delete/Scan` 这些老朋友。
### Java 中使用 RocksDB
对于 Java 程序员来说,使用 RocksDB 非常简单。RocksDB 本身是 C++ 写的,但官方提供了 RocksJava(JNI 封装),Maven 加个依赖就能用:
```xml
org.rocksdb
rocksdbjni
10.9.1
```
然后就可以直接用了:
```java
public class RocksDBDemo {
public static void main(String[] args) throws RocksDBException {
// 加载本地库
RocksDB.loadLibrary();
// 打开数据库,指定一个本地目录作为存储路径
// RocksDB 会在这个目录下创建一堆文件来存储数据
try (Options options = new Options().setCreateIfMissing(true);
RocksDB db = RocksDB.open(options, "/tmp/my-rocksdb")) {
// 写入
db.put("name".getBytes(StandardCharsets.UTF_8),
"javadoop".getBytes(StandardCharsets.UTF_8));
db.put("city".getBytes(StandardCharsets.UTF_8),
"paris".getBytes(StandardCharsets.UTF_8));
// 读取
byte[] value = db.get("name".getBytes(StandardCharsets.UTF_8));
String name = value == null ? null : new String(value, StandardCharsets.UTF_8);
// 删除
db.delete("city".getBytes(StandardCharsets.UTF_8));
// 范围扫描
try (RocksIterator iterator = db.newIterator()) {
// 从头开始遍历所有 key-value 对
for (iterator.seekToFirst(); iterator.isValid(); iterator.next()) {
String key = new String(iterator.key(), StandardCharsets.UTF_8);
String val = new String(iterator.value(), StandardCharsets.UTF_8);
System.out.println(key + " => " + val);
}
}
}
}
}
```
代码还是很直观的,没什么理解门槛。有几点需要注意,我们简单说一下:
1. **没有单独的进程**:这一点一定要强调。RocksDB 不像 MySQL、Redis 那样需要先启动一个服务,然后你的应用通过网络连接上去。RocksDB 没有单独的进程,没有端口,没有连接池,它就是一个库,编译进你的应用里,跑在你的应用进程中。你调用 `RocksDB.open()` 就相当于在你的进程内部打开了一个数据库,数据就存在你指定的本地目录里。
2. **字节数组**:API 层面操作的全是 `byte[]`,所以你需要自己处理序列化/反序列化。上面的例子为了简单直接用了 `String.getBytes()`,实际项目中你可能会用 Protobuf、JSON 或者其他序列化方式。
3. **资源管理**:RocksDB 的 Java 对象底层是 C++ 资源,用完记得关闭(推荐用 try-with-resources),否则会有内存泄漏。
4. **key 设计**:前面我们说过,RocksDB 的 key 是按字节序有序存储的。所以你后面如果要做范围扫描,key 的编码方式一定要提前设计好。比如时间戳、用户 ID、业务前缀怎么拼,这些都不是小事。
你可能会说,这不就是一个本地版的 Redis 吗?某种意义上可以这么理解,但两者有本质区别:Redis 的数据主要在内存中,RocksDB 的数据主要在磁盘上。所以 RocksDB 可以存储远超内存大小的数据量,而且重启后数据还在,不需要什么 RDB/AOF 恢复。
## RocksDB 是怎么跑在 JVM 里的
RocksDB 没有 Server 进程,它就是一个库。`RocksDB.open()` 这一行背后,它会通过 JNI 调用 C++ 代码:读取 MANIFEST 恢复元信息、回放 WAL 恢复上次没来得及 Flush 的数据、启动后台线程池。返回的 `RocksDB` 实例是线程安全的,直接注册成 Spring 的单例 Bean 就行。调用 `db.put()` 时,JNI 是在你当前这个 Java 线程上直接跑 C++ 代码的,不会做线程切换,也不会异步——哪个线程发起调用,就阻塞在哪里,直到 C++ 那边返回。
有两个点特别容易被忽略,我们单独强调一下:
1. **内存归属**。MemTable、Block Cache 这些都是 C++ 侧分配的堆外内存,不受 JVM 的 `-Xmx` 管。规划机器内存时一定要把它们单独算进去,别让 JVM 堆 + RocksDB 的内存超过物理内存。
2. **后台线程**。`open()` 之后 RocksDB 会在 C++ 侧启动一组后台线程,负责 Flush(把 Immutable MemTable 写成 SST)和 Compaction(合并整理 SST),这些工作会持续消耗 CPU 和磁盘 I/O。排查线上问题时,除了盯 Java 代码,也要意识到 RocksDB 自己一直在后台干活。线程数可以通过 `options.setMaxBackgroundJobs()` 控制。
简单说,RocksDB 的生命周期就是跟着 JVM 进程走的:进程启动时 open,进程关闭时 close,中间没有网络通信、没有连接池,一切都在进程内部完成。
好了,下面正式进入架构部分。
## 整体架构
先来一张官方的架构总览图,让大家对 RocksDB 有个全局的认识。
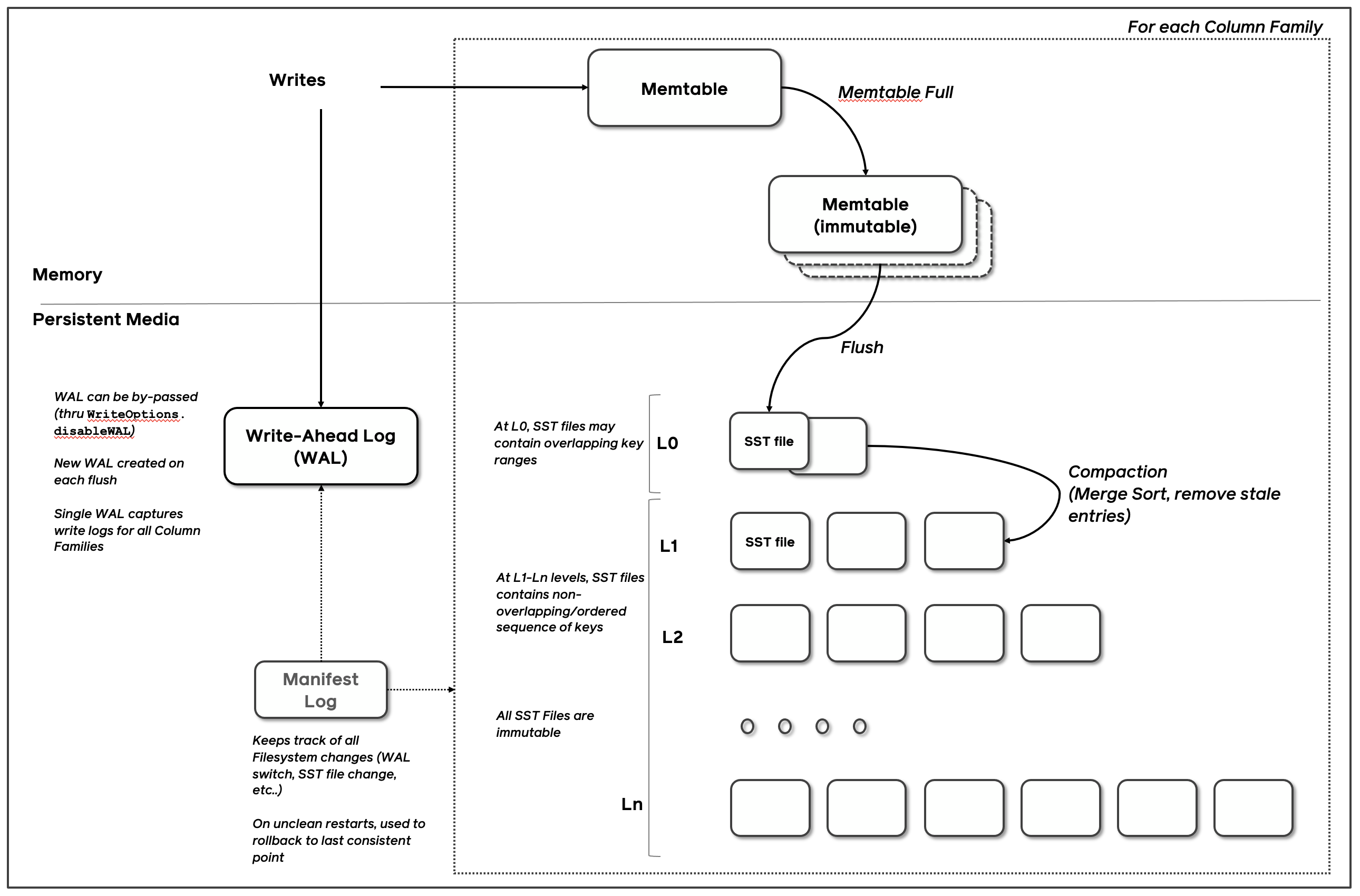
大方向上,RocksDB 的数据流是这样的:
1. **写入**时,数据先写入 WAL(Write Ahead Log,预写日志)保证持久性,然后写入内存中的 MemTable
2. 当 MemTable 写满后,它会变成 Immutable MemTable(只读),然后被 Flush 到磁盘上,生成一个 SST 文件(Sorted String Table)
3. 磁盘上的 SST 文件按层级组织(Level 0, Level 1, ...),通过 Compaction 不断合并、整理
4. **读取**时,先查 MemTable,再查 Immutable MemTable,最后查磁盘上的 SST 文件
这就是经典的 LSM-Tree(Log-Structured Merge-Tree)架构。到这里,大家脑子里最好先有一条主线:写入先进内存,再落磁盘,磁盘文件再由后台慢慢整理。先把这条主线抓住,后面就不容易乱。
好了,下面我们一个模块一个模块往下拆。
## LSM-Tree 核心思想
在深入 RocksDB 各个组件之前,我们先来理解一下 LSM-Tree 的核心思想,这个非常非常重要。前面我们已经提到它了,这里再单独拎出来说清楚。
传统的 B+ 树结构(比如 MySQL 的 InnoDB)是读优化的:数据在磁盘上是有序组织的,读取很快,但是写入时可能需要随机 I/O 来维护这个有序性。
而 LSM-Tree 正好相反,它是写优化的。核心思想就一句话:把随机写转化成顺序写。
怎么做到的?其实很简单:
1. 写入先到内存(MemTable),内存中的操作随便你怎么搞,不涉及磁盘
2. 内存攒够一批后,一次性顺序写到磁盘(Flush)
3. 磁盘上的文件后续通过后台 Compaction 来合并整理
这样一来,所有的磁盘写入都是顺序写,对 HDD 友好,对 SSD 更友好(减少写放大,延长寿命)。
当然,天下没有免费的午餐。写入快了,读取就要付出代价了,你可能需要查多个层级的文件才能找到一个 key。不过也没关系,这正是 RocksDB 后面那些设计存在的意义,比如 Bloom Filter、Block Cache、Compaction,本质上都是在给这个问题擦屁股。后面我们会详细说。
## MemTable
MemTable 是 RocksDB 的写入缓冲区,所有写操作(Put、Delete、Merge)都会先写到这里。
### MemTable 的数据结构
RocksDB 默认使用 SkipList(跳表)作为 MemTable 的底层数据结构。为什么选跳表?这个问题其实挺自然的,我们简单想一想:
- 支持高效的插入和查找,时间复杂度都是 O(log n)
- 支持有序遍历,这在 Flush 的时候很重要,因为生成的 SST 文件需要数据是有序的
- 实现相对简单,并发性能好
除了 SkipList,RocksDB 还支持其他几种 MemTable 实现。这里我们简单认识一下就够了,不要在这里停留太久:
- **SkipList**(默认):读写比较均衡,支持并发写入,通用场景基本都能用
- **HashSkipList**:在某些前缀查找场景下更有优势
- **HashLinkList**:更偏节省内存,但适用面没那么广
- **Vector**:实现比较简单,更适合一些特殊场景,比如批量导入
大多数情况下用默认的 SkipList 就够了,其他的先知道有这么回事就行。不要在这里纠结太久,先继续往下走。
### 写入流程
我们来看一次 Put 操作的核心流程:
```cpp
// 下面这段是为了讲主流程写的伪代码,不是 RocksDB 源码原样
Status DB::Put(const WriteOptions& options,
const Slice& key, const Slice& value) {
WriteBatch batch;
// 1. 将操作封装到 WriteBatch 中
batch.Put(key, value);
// 2. 调用 Write 方法执行写入
return Write(options, &batch);
}
Status DBImpl::Write(const WriteOptions& write_options, WriteBatch* batch) {
// 3. 先写 WAL(如果没有禁用的话)
// WAL 保证了即使进程崩溃,数据也不会丢
status = WriteToWAL(batch);
// 4. 然后写入 MemTable
// 这里是内存操作,很快
status = WriteBatchInternal::InsertInto(batch, mem_table);
// 5. 检查 MemTable 是否写满了
// 如果满了,就要切换一个新的 MemTable
if (mem_table->ApproximateMemoryUsage() > write_buffer_size) {
// 当前 MemTable 变成 Immutable
// 创建一个新的 MemTable 接收后续写入
// 触发后台 Flush
SwitchMemtable();
}
return status;
}
```
上面的代码还是比较简单的,关键就是两步:先写 WAL,再写 MemTable。大家可能注意到了,即使只是一个简单的 Put,也会先包装成 WriteBatch。没错,在 RocksDB 内部,WriteBatch 才是写入的最小执行单元,单条写入和批量写入走的是同一条路径。
这个设计我个人觉得是很自然的。因为你只要想支持批量写、原子写、多线程合并写,那最后一定会收敛到"先把操作收集起来,再统一执行"这个方向。
这里有几个值得注意的点:
1. **WriteBatch**:一个 WriteBatch 里面可以包含多个 Put/Delete 操作,它们要么全部成功,要么全部失败,保证原子性。
2. **write_buffer_size**:这个参数控制单个 MemTable 的大小,默认 64MB。MemTable 到达这个大小后就会变成 Immutable,然后被 Flush 到磁盘。
3. **SwitchMemtable**:当 MemTable 满了之后,并不是直接 Flush,而是先把它标记为 Immutable(只读),同时创建一个新的 MemTable,这样写入就不会被阻塞。
### 并发写入:Writer Group
这里有个很精妙的设计值得一提。多个线程同时写入时,RocksDB 不是简单地用一把大锁来串行化,而是采用了 Writer Group(也叫 Group Commit)的机制。这个地方如果你第一次看到,可能会觉得有点高级,但其实思想很朴素:
1. 多个写入线程到达时,第一个线程成为 Leader
2. Leader 把自己和其他等待线程的 WriteBatch 合并成一个大的 batch
3. Leader 一次性将合并后的 batch 写入 WAL 和 MemTable
4. 写完后通知其他线程:"你们的数据也写好了"
这样就把多次小的 I/O 合并成了一次大的 I/O,大大提高了吞吐量。说白了就是"攒一波,一起提交"。很多高性能系统,本质上都是这个套路,只不过名字起得不一样而已。
## WAL(Write Ahead Log)
WAL 是 RocksDB 保证数据持久性的关键机制。简单来说:数据在写入 MemTable 之前,一定会先写入 WAL。这样即使进程崩溃了,重启后也能从 WAL 中恢复还没来得及 Flush 到磁盘的数据。
这个点大家一定要记住,因为后面很多行为都能从这里推出去。为什么重启之后数据还能回来?为什么 close 不是 flush?为什么写入性能和持久性之间会有取舍?往前倒,基本都能倒回 WAL。
### WAL 的内部结构
下面这部分是 WAL 内部的存储格式细节,不影响理解主流程。如果你只想把握大方向,可以跳到下一小节"WAL 的生命周期"继续看。
WAL 文件内部按固定 32KB 大小的 Block 来组织,每个 Block 里面包含若干条 Record:
```
WAL 文件:
┌─────────────────┬─────────────────┬─────────────────┬─────┐
│ Block (32KB) │ Block (32KB) │ Block (32KB) │ ... │
└─────────────────┴─────────────────┴─────────────────┴─────┘
每个 Block 内部:
┌──────────┬──────────┬──────────┬─────┐
│ Record 1 │ Record 2 │ Record 3 │ ... │
└──────────┴──────────┴──────────┴─────┘
每个 Record:
┌──────────┬────────┬──────┬─────────────┐
│ CRC (4B) │ Len(2B)│Type │ Data │
│ │ │(1B) │ (WriteBatch) │
└──────────┴────────┴──────┴─────────────┘
```
每个 Record 包含一个 CRC 校验码、数据长度、类型标识和实际的 WriteBatch 数据。当一个 WriteBatch 比较大,一个 Block 装不下的时候,就需要拆成多条 Record 分布在多个 Block 中,Type 字段就是用来标识这种情况的:
- **kFull**:这条 Record 包含了完整的 WriteBatch 数据,没有跨 Block
- **kFirst**:WriteBatch 太大了,一个 Block 装不下,这是第一个分片
- **kMiddle**:中间的分片
- **kLast**:最后一个分片
### WAL 的生命周期
这里有个点很容易讲错,我们专门说一下:不要把 WAL 和某一个 MemTable 理解成严格的一一对应关系。
更准确一点的理解是:
1. WAL 负责记录写入日志,它记录的是数据库的写入顺序
2. MemTable 负责承接当前可写的数据,写完 WAL 之后,数据还会进入 MemTable
3. 多个 Column Family 共享 WAL,但每个 Column Family 可以有各自的 MemTable
4. Flush、WAL 切换、WAL 删除是相关联但不完全等价的几件事
说白了就是,WAL 更像"写入流水账",MemTable 更像"当前内存工作区"。两者会互相配合,但不要机械地认为"一个 WAL 只服务一个 MemTable"。
那 WAL 什么时候可以删除呢?简单理解就是:当 WAL 里记录的那部分数据,已经可以通过别的持久化状态安全恢复时,这个 WAL 才有机会被回收。比如相关 MemTable 已经 Flush 成 SST 了,或者系统的恢复点已经推进了。这里不展开更细的实现细节,先有这个概念在心里就够了。
这里还有个细节:WAL 文件默认是追加写入的,但默认不会在每次写入后都做 fsync(除非你设置了 `WriteOptions::sync = true`)。这个区别一定要注意:
- 进程崩溃:已经写进内核页缓存、并且还在 WAL 里的数据,通常还有机会在重启时恢复
- 机器掉电 / 操作系统崩溃:因为没有强制 fsync,最近几次写入就可能真的丢失
所以 `sync=false` 不是"完全不持久化",而是"持久性保证没有那么强"。如果你需要更强的持久性保证,可以打开 sync 选项,代价当然就是写入性能下降。
## SST 文件
SST(Sorted String Table)是 RocksDB 在磁盘上存储数据的基本单元。当 Immutable MemTable 被 Flush 到磁盘时,就会生成一个 SST 文件。
前面我们一直在说"落盘""落盘",落到哪里?说白了,最后就是落成这种 SST 文件。
### SST 文件的内部结构
RocksDB 默认使用 BlockBasedTable 格式,我们来看看它的结构:
```
┌─────────────────────────────────┐
│ Data Block 1 │ ← 存储实际的 key-value 数据
├─────────────────────────────────┤
│ Data Block 2 │
├─────────────────────────────────┤
│ ... │
├─────────────────────────────────┤
│ Data Block N │
├─────────────────────────────────┤
│ Meta Block │ ← 存储 Bloom Filter 等元信息
│ (Filter Block) │
├─────────────────────────────────┤
│ Meta Block │
│ (Stats Block) │
├─────────────────────────────────┤
│ Meta Index Block │ ← Meta Block 的索引
├─────────────────────────────────┤
│ Index Block │ ← Data Block 的索引
├─────────────────────────────────┤
│ Footer │ ← 指向 Index Block 和 Meta Index Block
└─────────────────────────────────┘
```
从它的名字 BlockBasedTable 也可以看得出来,它的基础单位是 block,sst 文件内部是各种 block。有几个重点:
1. **Data Block**:存放实际的 key-value 对,默认 4KB 一个 block。block 内部的 key 是有序的,并且用了前缀压缩来节省空间(相邻 key 共享前缀的部分不重复存储)。
2. **Index Block**:存放每个 Data Block 的索引信息(每个 block 的最后一个 key + block 的 offset)。查找时先二分查找 Index Block,定位到具体的 Data Block,再在 block 内部查找。
3. **Filter Block**:存放 Bloom Filter,用来快速判断一个 key 是否不在这个 SST 文件中。注意,Bloom Filter 只能告诉你"一定不在"或"可能在",不能确定告诉你"一定在"。
4. **Footer**:固定大小,位于文件末尾,存放 Index Block 和 Meta Index Block 的位置信息。读取 SST 文件时,先读 Footer,然后就知道去哪里找 Index 了。
### Data Block 内部结构
下面这一小节是 Data Block 内部的编码细节,属于偏底层的优化设计。第一次看可以跳过,不影响后面的理解。
先别被图吓到,抓住两个词就行:前缀压缩、restart point。
```
┌───────────────────────────────────────────────┐
│ Record 1: shared_bytes | unshared_bytes | │
│ value_length | key_delta | value │
├───────────────────────────────────────────────┤
│ Record 2: ... │
├───────────────────────────────────────────────┤
│ ... │
├───────────────────────────────────────────────┤
│ Record N: ... │
├───────────────────────────────────────────────┤
│ Restart Point 1 (4 bytes) │
│ Restart Point 2 (4 bytes) │
│ ... │
│ Number of Restart Points (4 bytes) │
└───────────────────────────────────────────────┘
```
这里用了前缀压缩(prefix compression)。比如连续的 key 是 "user:001"、"user:002"、"user:003",那第二个 key 只需要存储 `shared_bytes=5`(和前一个 key 共享的前缀长度)+ `key_delta="002"`(不同的部分)。
Restart Point 是用来加速二分查找的。每隔若干条记录(默认 16 条),就设一个 restart point,这个位置的 key 会存储完整的 key(不做前缀压缩),这样二分查找时可以直接跳到 restart point 来比较。
## 读取流程
说完了写入和存储,我们来看看读取。前面那一堆东西,最终都是为了回答一个问题:我现在拿着一个 key 来查,你到底怎么把 value 给我找出来?
不过在正式看读取流程之前,我们得先补一个非常关键的前置知识,不然后面的很多话都会悬在空中。这里有点跳,我先解释一下。
### 先理解一个前置概念:同一个 key 可能有多个版本
如果你之前接触的是比较"表层"的数据库接口,可能会天然觉得:一个 key 对应一个 value,更新之后旧值就没了。
但 RocksDB 内部不是这么简单。你如果把 RocksDB 也理解成"一个 key 永远只对应一个 value",后面基本就全乱了。
大方向上,我们可以先这样理解:
1. 同一个 user key 在 RocksDB 内部可能同时存在多个版本
2. 每次写入,都会带上一个更"新"的顺序信息
3. Delete 也不是立刻把磁盘上的旧数据抹掉,而是先写入一个 tombstone(删除标记)
4. 后续在 Compaction 的过程中,旧版本和已经可以回收的删除标记才会被真正清理掉
这也是为什么前面我们一直在说"Compaction 不只是合并文件,它还会清理旧版本数据"。
所以你在理解读取流程的时候,脑子里要有这样一个画面:读取不是简单地在很多地方找一个 key,而是在很多地方找这个 key 的"最新可见版本"。
如果还要继续深挖,那后面就会涉及 internal key、sequence number、snapshot 这些概念,我在[第二篇文章](/post/rocksdb-deep-dive)里会专门展开。不过这篇文章我们先不钻这么深,先把主流程搞明白。
### Get 操作的大致路径
RocksDB 的读取流程(Get 操作)大致按以下顺序进行:
```
Get(key)
│
├──① 查 MemTable(当前活跃的)
│ └── 找到了?→ 返回
│
├──② 查 Immutable MemTable(可能有多个)
│ └── 找到了?→ 返回
│
├──③ 查 Level 0 的 SST 文件
│ 注意:Level 0 的文件之间 key 范围可能重叠!
│ 需要按新旧顺序逐个查找
│ └── 找到了?→ 返回
│
├──④ 查 Level 1 的 SST 文件
│ Level 1 及以下,每层内部的文件 key 范围不重叠
│ 可以用二分查找定位到具体文件
│ └── 找到了?→ 返回
│
├──⑤ 查 Level 2 ...
│
└──⑥ 一直查到最后一层
```
这里有个关键的区别:Level 0 的 SST 文件之间 key 范围是可以重叠的(因为每次 Flush 都直接生成 Level 0 文件),而 Level 1 及以下每层内部的文件 key 范围通常不重叠(因为经过了 Compaction 整理)。
所以查 Level 0 时往往需要检查多个文件,而且一般要优先看更新的文件;而查其他层级时,通常可以先定位到目标范围附近的文件,再继续往下查。这也是为什么 Level 0 文件太多会影响读取性能。
### Block Cache
每次读取都要走磁盘肯定不行,RocksDB 用 Block Cache 来缓存热点数据。
Block Cache 是一个 LRU Cache(也支持 Clock Cache),缓存的单位是 Data Block。当你读取某个 key 时,它所在的整个 Data Block 都会被加载到 Block Cache 中,下次读取同一个 block 里的其他 key 就不需要再读磁盘了。
```java
BlockBasedTableConfig tableConfig = new BlockBasedTableConfig();
// 设置 Block Cache 大小为 512MB
tableConfig.setBlockCache(new LRUCache(512 * 1024 * 1024));
// Data Block 大小,默认 4KB
tableConfig.setBlockSize(4 * 1024);
```
一般建议把 Block Cache 设得大一些,尤其是读多写少的场景。这个东西非常现实,缓存够大,很多问题会立刻变得没那么明显。
### Bloom Filter
前面提到了 Bloom Filter,这里再详细说一下。在读取时,对于每个可能包含目标 key 的 SST 文件,RocksDB 可以先用 Bloom Filter 快速判断 key 是否在这个文件中。如果 Bloom Filter 说"不在",那就直接跳过这个文件,不需要读取 Data Block。
这在 key 不存在的情况下特别有用——不需要翻遍所有层级的文件。
```java
// 启用 Bloom Filter,每个 key 用 10 bits
tableConfig.setFilterPolicy(new BloomFilter(10));
```
这里的参数 10 表示每个 key 使用 10 个 bit 来构建 Bloom Filter,这样假阳性率大概在 1% 左右。bits 越多,假阳性率越低,但占用的内存和磁盘空间也越多。一般来说 10 就够了,不需要调太高。很多时候不是参数越大越高级,这个大家一定要有数。
## Compaction
Compaction 可以说是 LSM-Tree 中最复杂也最重要的机制了。我们前面说了,数据是先写到 MemTable,然后 Flush 到 Level 0,这样 Level 0 的文件会越来越多。如果不做任何整理,读取性能会不断恶化。
所以大家要有一个概念:RocksDB 不是"写完就完事了"。很多真正麻烦的工作,其实都是后台慢慢做掉的。
Compaction 做的事情就是:把多个 SST 文件合并成更少的、更有序的文件,同时清理被新版本覆盖的旧数据,以及已经可以回收的删除标记。
### Level Style Compaction(默认)
RocksDB 默认使用 Leveled Compaction,我们来看看它是怎么工作的:
```
Flush 之后:
Level 0: [SST_a] [SST_b] [SST_c] ← 文件之间 key 范围可能重叠
Level 1: [SST_1] [SST_2] [SST_3] ← 文件之间 key 范围不重叠
Level 2: [SST_x] [SST_y] ... [SST_z]
Compaction 触发条件:
- Level 0: 文件数量超过阈值(默认 4 个)
- Level 1+: 该层数据总大小超过阈值
```
当 Level 0 文件数量超过 `level0_file_num_compaction_trigger`(默认 4)时,就会触发 Compaction。具体过程:
1. 从 Level 0 中选出一批文件
2. 找出这些文件 key 范围在 Level 1 中有重叠的文件
3. 把这些文件一起读出来,做一次多路归并排序
4. 生成新的 Level 1 文件,删除旧文件
Level 1 到 Level 2、Level 2 到 Level 3 以此类推。每一层的容量是上一层的 10 倍(由 `max_bytes_for_level_multiplier` 控制,默认 10)。
```
Level 0: 最多 4 个文件(触发 Compaction 的阈值)
Level 1: 256 MB(max_bytes_for_level_base 默认值)
Level 2: 2.56 GB
Level 3: 25.6 GB
Level 4: 256 GB
...
```
### 写放大问题
Compaction 有一个不可回避的问题——写放大(Write Amplification)。
什么意思呢?你往 RocksDB 写入 1 字节的数据,由于 Compaction 的原因,实际写入磁盘的数据量可能是几十甚至上百字节。因为同一份数据可能在 Level 0 到 Level N 的 Compaction 过程中被反复读取和写入。
对于 Leveled Compaction,写放大通常会比较明显,但具体能有多大,并没有一个放之四海而皆准的固定数字。它会受到层级大小、数据分布、更新模式、压缩配置等因素影响。这在 HDD 上可能不是什么大问题,但在 SSD 上就需要关注了,因为 SSD 的写入寿命是有限的。
### 其他 Compaction 策略
除了默认的 Leveled Compaction,RocksDB 还支持另外两种策略:
**Universal Compaction**:
- 适合写多读少、对写放大敏感的场景
- 简单理解就是:当 Level 0 文件积累够多之后,把它们合并成一个大文件
- 写放大比 Leveled 低,但空间放大更大(因为合并前需要保留新旧两份数据)
**FIFO Compaction**:
- 适合类似缓存或时序数据的场景
- 最简单粗暴:只保留最近一段时间的数据,过期的文件直接删除
- 几乎没有写放大,但只适用于数据有 TTL 的场景
怎么选?大多数场景用默认的 Leveled Compaction 就好。如果你的场景写入量特别大、对写放大敏感,可以考虑 Universal。FIFO 适用面比较窄,了解一下就行。
个人感觉,很多文章喜欢把这几个策略讲得很花,但对大部分读者来说,先把默认的 Leveled Compaction 理解透,就已经很够用了。
## Column Family
Column Family 是 RocksDB 中一个非常实用的特性。简单来说,一个 RocksDB 实例可以包含多个 Column Family,每个 Column Family 是一个独立的 key 命名空间。
你可以把它理解为一个数据库中的不同"表",但比"表"更轻量——它们共享 WAL,但有独立的 MemTable 和 SST 文件。
```java
// Column Family 描述列表
List cfDescriptors = Arrays.asList(
// 默认的 Column Family,必须有
new ColumnFamilyDescriptor(RocksDB.DEFAULT_COLUMN_FAMILY),
// 自定义的 Column Family
new ColumnFamilyDescriptor("user_data".getBytes()),
new ColumnFamilyDescriptor("metadata".getBytes())
);
List cfHandles = new ArrayList<>();
DBOptions dbOptions = new DBOptions()
.setCreateIfMissing(true)
.setCreateMissingColumnFamilies(true);
RocksDB db = RocksDB.open(dbOptions, "/path/to/db", cfDescriptors, cfHandles);
// 向不同的 Column Family 写入数据
db.put(cfHandles.get(0), "key1".getBytes(), "value1".getBytes()); // default
db.put(cfHandles.get(1), "key2".getBytes(), "value2".getBytes()); // user_data
db.put(cfHandles.get(2), "key3".getBytes(), "value3".getBytes()); // metadata
```
Column Family 有几个好处:
1. **逻辑隔离**:不同类型的数据可以存放在不同的 Column Family 中
2. **独立配置**:每个 Column Family 可以有不同的 Compaction 策略、压缩算法等
3. **原子跨 CF 写入**:通过 WriteBatch 可以实现跨 Column Family 的原子写入
4. **独立删除**:可以直接 Drop 一整个 Column Family,比逐个 Delete key 快得多
## 性能调优指南
最后,我们来聊聊 RocksDB 的性能调优。这部分算是实战经验了,不一定每个参数你都会用到,但了解一下总是好的。
不过我先说一句实话:调优 RocksDB,不是把参数表背下来就行了。真正有用的做法是先判断你的场景到底是写多、读多、点查多、范围扫描多,还是磁盘空间特别紧张。不同场景,关注点完全不一样。
我们先把前面文章中提到的默认配置汇总一下,方便大家对照:
- **write_buffer_size**:单个 MemTable 的大小,默认 64MB
- **MemTable 数据结构**:默认 SkipList
- **WAL sync**:默认关闭(不 fsync)
- **Data Block 大小**:默认 4KB
- **Restart Point 间隔**:默认每 16 条记录
- **Compaction 策略**:默认 Leveled Compaction
- **level0_file_num_compaction_trigger**:Level 0 文件达到多少个时触发 Compaction,默认 4
- **max_bytes_for_level_multiplier**:每层容量倍数,默认 10
- **max_bytes_for_level_base**:Level 1 的目标大小,默认 256MB
下面我们看看在 Java 中怎么配置这些参数。不过还是那句话,不要试图把这些参数硬背下来,先知道它们分别影响什么就行。
### 写入优化
如果你的场景是写多读少,或者写入高峰很明显,那这一组参数要重点关注:
```java
Options options = new Options();
// 1. MemTable 大小,默认 64MB
// 增大这个值可以减少 Flush 频率,但会增加内存占用和恢复时间
options.setWriteBufferSize(128 * 1024 * 1024); // 128MB
// 2. 最多同时存在多少个 Immutable MemTable
// 如果 Flush 速度跟不上写入速度,增大这个值可以避免写入被阻塞
options.setMaxWriteBufferNumber(4);
// 3. Level 0 文件达到多少个时触发 Compaction
options.setLevel0FileNumCompactionTrigger(4);
// 4. Level 0 文件达到多少个时开始减慢写入
// 这是一个"限流"机制,避免 Compaction 跟不上写入
options.setLevel0SlowdownWritesTrigger(20);
// 5. Level 0 文件达到多少个时完全停止写入
// 到这一步说明 Compaction 严重跟不上了
options.setLevel0StopWritesTrigger(36);
// 6. 后台 Compaction 和 Flush 的线程数
// 在 SSD 上可以适当增大
options.setMaxBackgroundJobs(6);
```
### 读取优化
如果你的场景是点查很多,或者大量读取热点 key,那除了前面提到的 Block Cache 和 Bloom Filter 基础配置之外,下面这些进阶参数也值得关注:
```java
BlockBasedTableConfig tableConfig = new BlockBasedTableConfig();
tableConfig.setBlockCache(new LRUCache(1024 * 1024 * 1024)); // 1GB
tableConfig.setFilterPolicy(new BloomFilter(10));
// 把 Index Block 和 Filter Block 也放到 Block Cache 中
// 默认只缓存 Data Block,这两个不缓存的话每次都要从磁盘读
tableConfig.setCacheIndexAndFilterBlocks(true);
// pin 住 L0 和 L1 的 Index/Filter Block,不让它们被 evict
// 因为这些层级被查询的概率最高,淘汰掉反而浪费
tableConfig.setPinL0FilterAndIndexBlocksInCache(true);
// 别忘了把 tableConfig 设置到 options 上
options.setTableFormatConfig(tableConfig);
```
### 压缩配置
如果你的场景是磁盘空间比较紧张,或者底层数据量很大,那压缩配置就值得认真调一调。
```java
// 不同层级使用不同的压缩算法
// Level 0 和 Level 1 不压缩(减少 CPU 开销,这两层数据量小)
// Level 2 及以下用 LZ4 或 Zstd 压缩(数据量大,值得压缩)
List compressionPerLevel = Arrays.asList(
CompressionType.NO_COMPRESSION, // Level 0
CompressionType.NO_COMPRESSION, // Level 1
CompressionType.LZ4_COMPRESSION, // Level 2
CompressionType.LZ4_COMPRESSION, // Level 3
CompressionType.LZ4_COMPRESSION, // Level 4
CompressionType.LZ4_COMPRESSION, // Level 5
CompressionType.ZSTD_COMPRESSION // Level 6(最底层用压缩比更高的 Zstd)
);
options.setCompressionPerLevel(compressionPerLevel);
```
这里不展开说各种压缩算法的对比了,简单来说:LZ4 快但压缩比一般,Zstd 压缩比高但稍慢。最底层数据量最大,所以用 Zstd 更合适。感兴趣的读者可以自己再去查一查各种压缩算法的 benchmark,这里我们就不展开了。
## 总结
好了,到这里整篇文章就差不多了。我们来总结一下 RocksDB 的核心要点:
1. **LSM-Tree 架构**:核心思想是把随机写转化为顺序写,是一个写优化的存储引擎
2. **写入路径**:数据先写 WAL(保证持久性),再写 MemTable(内存中的跳表),MemTable 满了后 Flush 到磁盘生成 SST 文件
3. **读取路径**:按 MemTable → Immutable MemTable → Level 0 → Level 1 → ... 的顺序查找,通过 Block Cache 和 Bloom Filter 来加速
4. **Compaction**:是 LSM-Tree 的核心维护机制,通过合并 SST 文件来保证读取性能,但会带来写放大问题
5. **SST 文件**:内部按 Block 组织,使用前缀压缩、Bloom Filter、多级索引等技术来优化存储和查询效率
6. **Column Family**:提供了一个 RocksDB 实例内的逻辑隔离能力
7. **性能调优**:核心是在写放大、读放大和空间放大之间找到适合你场景的平衡点
RocksDB 的设计哲学可以用一句话概括:为写入而生,为读取而优化。它不是万能的,如果你的场景是读远多于写、需要复杂查询,那关系型数据库可能是更好的选择。但在高吞吐写入、嵌入式存储这些场景下,RocksDB 确实是目前最成熟可靠的选择之一。
如果你是第一次接触 RocksDB,我觉得这篇文章看到这里就够了。先把 WAL、MemTable、SST、Compaction 这四个东西放到脑子里,后面不管是做技术选型、看调优文档、还是排查线上问题,思路就不会乱。
如果还想继续往下深挖,下一步建议重点看看这几个东西:internal key、sequence number、snapshot、MANIFEST、VersionSet。这些内容我已经写在了第二篇文章里:[RocksDB 架构设计与核心机制(2/2)](/post/rocksdb-2),专门沿着本篇的四条主线把这些细节补上。
(全文完)