这篇文章终于写完了。一开始没想那么多,写出来发现真的蛮长的,但自己仔细检查过非常多次,应该上手难度很低。
本文就是一时兴起,想写一篇给 Javaer 的 Rust 入门,很多 Java 开发者,都对这门语言感兴趣,但是可能因为它的学习路线非常陡峭而放弃。事实也确实如此,这门语言里的不少概念,比如所有权、借用检查、生命周期,对 Java 程序员来说是完全陌生的,但反过来想,Rust 里也有大量的东西,我们其实在 Java 里早就见过了,只是名字不同而已。还有这几年 Java 的升级,其实也借鉴了很多 Rust 上的东西。
而且现在有了 AI Coding 的加持,其实我们不必像过去一样,非常精通一门语言才能开始使用它,只要能看得懂语法,知道它的玩法,它就可以成为你的一个技能点。
我工作这么多年,主力语言一直是 Java 和前端的一些技术栈。两三年前开始使用 Rust,我觉得它是非常有趣的语言,是那种能带给我们新的思考的语言。
我希望本文是一篇有趣的文章,也是一篇有用的文章。我会通过对比大家熟悉的 Java,来帮助大家理解 Rust 的各种内容。
作为本文的读者,默认你写过几年 Java,对 JVM、Maven、泛型、lambda、并发这些都了解。本文不会讲“在 Rust 里面什么是变量?”这种东西,但是会和 Java 做不少的对比,再加上要学习的概念确实不少,所以本文不会太短。感兴趣的可以按章节慢慢看,不一定要一口气读完,我争取让每一节都足够简单好理解,还有就是很多细节可能看第一遍的时候是不太懂的,这其实也没太大的关系,看完全文再倒回去看可能就豁然开朗了。
Rust 和 Java 是不同的设计方向
学 Rust 的时候最大的感受不是语法难,而是它老是在逼你换一种写代码的方式。
写 Java 代码,大家脑子里都是这些:
- 对象统统在堆上,变量里放的是引用。
- 对象什么时候释放,交给 GC,我们不关心。
- 参数传来传去,本质都是引用拷贝,多个变量可以指向同一个对象。
- 多线程共享对象,靠
synchronized、Lock、volatile、并发容器兜底。 - 空值用
null,异常用try/catch。
这些东西太自然了,自然到我们平时根本不会多想。Rust 麻烦就麻烦在这里,它几乎把这些全部改掉了。Rust 的设计其实在做一件很朴素的事:把 Java 里很多运行时才会暴露的问题,提前到编译期解决掉:
- Java 里可能 NPE,Rust 用
Option<T>逼你处理。 - Java 里可能忘记 catch,Rust 用
Result<T, E>逼你处理。 - Java 里可能两个线程同时改一个对象,Rust 用所有权和
Send/Sync逼你说清楚。 - Java 里对象什么时候被释放靠 GC,Rust 在编译期就把每个值的销毁点算清楚。
也就是说,这两门语言架构上的核心差别就一句话:Java 中间有 JVM 和 GC 帮你兜底,而 Rust 让编译器在编译期把规则检查完。这也是为什么 Rust 的编译器看起来很烦,初学者会一直在跟编译器做斗争,想要写出可编译的代码可能就已经要了老命了。
大家把这几条记心里就行,后面我们会逐步介绍其细节。
一、工具链:rustup 就是 Rust 的 SDKMAN
我们先来看看 Rust 的工具链,这部分其实最容易上手,因为基本就是 Java 生态那一套换了个名字。
Java 这边我们装环境,先有 JDK,里面带 javac、java、jar、javadoc、jshell 这些工具;如果要管理多个 JDK 版本,会用 SDKMAN 或者 jenv。
Rust 这边对应的关系是这样的:
rustup:版本管理工具,对应 SDKMAN/jenv,负责下载、切换 Rust 工具链rustc:编译器,对应 javaccargo:构建+包管理,对应 Maven 或 Gradle(这个非常重要,后面单独讲)rustfmt:格式化,对应 google-java-formatclippy:lint 工具,对应 SonarLint / SpotBugsrust-src、rust-docs、rust-std:源码、文档、标准库
这一整套东西打包在一起叫 toolchain,统一通过 rustup 来管理。我们可以看到,Rust 把“代码风格一致性”当成语言体验的一部分,直接在 toolchain 中包含了 format、lint 等工具,让大家可以更好地管理代码风格与约束。
Rust 还分 stable、beta、nightly 三个版本,大致可以这么理解:
- stable:对应 Java 的 LTS,正常项目用这个
- beta:下一个 stable 候选版本
- nightly:每天构建的最新版,对应 Java 的 EA(early access),有些实验特性只在 nightly 上能用
常用命令我们看一眼:
# 安装 rustup(顺带把 stable 工具链装上)
curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
# 看版本,这个跟 java -version 一个意思
rustc --version
# 升级,rustup 会顺便把 cargo 也升了
rustup update
# 看当前用的是哪个 toolchain
rustup show
# 看当前 toolchain 装了哪些组件
rustup component list --installed
# 装 clippy(默认其实就装好了)
rustup component add clippy
# 切换版本,类似 sdk use java xxx
rustup install 1.90.0
rustup default 1.90.0
rustup default beta # 切换到 beta
rustup default nightly # 切换到 nightly
# 只在当前目录用某个版本,类似项目级别的版本配置
rustup override set nightly
rustup override set 1.95.0工具链装好以后,rustfmt 和 clippy 就可以直接用了:
cargo fmt # 代码格式化
cargo clippy # 代码质量检查我们是可以给 rustfmt 和 clippy 定制规则的,这是后话了,不做介绍。
到这里,工具链层面我们就跟 Java 对上号了。下面我们看看怎么写第一个程序。
二、Hello World
老规矩,写完 Hello World,就算入门 Rust 了。
写个 main.rs:
fn main() {
println!("Hello, world!");
}然后编译:
rustc main.rs这里要注意三个点:
- 入口函数叫
main,写法是fn main(),跟 Java 几乎一样。 println!后面有个感叹号,说明它不是普通函数,是个宏(macro),后面会讲。- 编译出来的是直接可执行的二进制文件,不像 Java 的
.class字节码,需要 JVM 才能跑。
./main这就是 Rust 的第一个核心区别:它没有运行时虚拟机,没有 GC,跟 C/C++ 一样编译成原生代码直接跑。这也是为什么 Rust 适合做系统编程、底层服务、CLI 工具,而 Java 由于 JVM 的存在,在启动速度和资源占用上一直是劣势。
不过,真实工程里我们基本不会直接用 rustc 来编译,就跟我们在 Java 里几乎不会直接用 javac 一样,都是用构建工具来组织。Rust 的构建工具叫 cargo。
三、Cargo:Rust 世界的 Maven
在装 rust 的时候顺手就装好了 cargo,跑 rustup update 升级 Rust 的时候 cargo 也跟着升。
我们直接看用法:
cargo new hello_cargo这个相当于 mvn archetype:generate,生成一个项目骨架。它其实只是帮我们创建 src/main.rs 和 Cargo.toml。
Cargo.toml 跟 pom.xml 的角色完全一样,都是项目配置文件,只不过格式是 TOML。看一眼:
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024" # Rust的语言版本,越高的版本支持越多的语法,目前最新是 2024
[dependencies]
# 在 java 里我们叫 jar 包,在 rust 里叫 crate
rand = "0.8.5"注意,edition 版本是语言层面的,不是前面说的 rustup 管理的 rustc、cargo、rustdoc, clippy 等 toolchain 的版本。当然了,你如果使用 edition=2024,肯定有最低的编译器版本要求的,不然旧版的编译器可能都不认识 edition 2024 新增的语法,根本没法编译。
接着是构建命令:
cargo build # 类似 mvn compile,默认编译出一个 debug 版本
cargo build --release # 类似 mvn package -P release,会做优化、去掉调试信息等,生成一个最终可用版本
cargo run # 类似 mvn exec:java,build + run 一条龙
cargo check # 只检查能不能过编译,不生成产物,速度快得多
cargo clean # 类似 mvn clean,把 target 目录删掉构建产物在 target/debug/ 或 target/release/ 下面。
这里要特别提一下 cargo check。Rust 的编译比 Java 慢得多(因为它要做单态化、借用检查这一堆事),所以日常写代码时常用 cargo check 看类型和借用规则能不能过,速度会快很多。等到要真正跑了再 cargo build。
依赖管理这块我们重点看一下:
cargo add axum@0.7.2 # 类似 mvn dependency:add(其实 javaer 都是手动复制粘贴依赖的),加依赖到 Cargo.toml
cargo update # 按 SemVer 兼容范围升级:1.2.3(即 ^1.2.3)会升到 <2.0.0;0.8.5(即 ^0.8.5)会升到 <0.9.0
cargo tree # 类似 mvn dependency:tree
cargo doc --open # 生成依赖的文档并打开,介绍各个API,其实没啥用,至少Java的docs,我们现在几乎是不看的这里有个 Cargo.lock 文件,作用跟 npm 的 package-lock.json 一样,确保依赖版本固定。Maven 没有这个东西,因为 Maven 的版本号本身就是固定的(除了 SNAPSHOT),但 Cargo 的版本号是语义化的范围("0.8.5" 实际表示 ">=0.8.5, <0.9.0"),所以需要 lock 文件来固化。
举个例子,假设我们第一次 build 的时候,没有 Cargo.lock 文件,编译器会去找一个满足条件的最大版本,假设找到了 0.8.9,那么这个版本号会写入到 Cargo.lock 文件,以后都会固定使用 0.8.9,即使以后有 0.8.100 我们也不会更新,因为版本被 lock 了,除非我们手动跑 cargo update,它才会更新 lock 文件。但还是那句话,如果你跑 cargo update 的时候,有 0.8.100 和 0.9.0,编译器会使用 0.8.100。另外,如果我们要精确使用 0.8.5,应该这么写
rand = "=0.8.5"。简单理解 SemVer 的规则:对于 0.y.z 的版本,更新最后一个数字到最新的,对于 x.y.z,如 1.2.5,它的语义范围是 [1.2.5, 2.0.0)
应用项目一般要把 Cargo.lock 提交到 git,库项目通常不太关心这个,按项目习惯来。
如果要用私有 registry,类似 Maven 的私服:
[dependencies]
my_crate = { version = "1.0", registry = "private-registry" }
[registries]
private-registry = { index = "https://your-private-cargo-registry.com" }这里有一个跟 Java 差异很大的地方需要特别说一下:Rust 不允许你"白嫖"上游的传递依赖。
什么意思呢?即使 a 依赖了 c,你的项目想用 c 的 API,也必须自己也在 Cargo.toml 里再写一遍 c。这样做的好处是,上游用了哪些依赖是它自己的实现细节,以后它升级或者换掉 c,都不会破坏你的代码。
再来看版本冲突的场景:假设你的项目依赖了 a 和 b,a 和 b 都依赖了 c,但是版本不一样。
在 Java 里,Maven 会做 dependency mediation,最终选一个版本,然后大家都用这个版本,可能就引发各种 NoSuchMethodError。
在 Rust 里,Cargo 会下载两个版本的 c,a 和 b 在链接的时候各自用各自的版本,不会有 Java 那种"依赖地狱"的问题。
跟 Java 还有一点很不一样的是包的设计风格。Rust 生态更喜欢把一个包做大、提供大量 features,使用方按需开启,比如 tokio:
tokio = { version = "1", features = ["rt-multi-thread", "macros"] }这个习惯的成因是:Rust 是静态编译的,编译器会做 dead code elimination,没用到的 feature 在最终产物里根本不存在。所以一个大包加 features 反而更高效,依赖管理也更简单。Java 那边就没这个传统,大家都做小包,比如 Spring 就有非常多的 jar 包。
Clippy 我们前面提过一嘴,它是 toolchain 的一部分,它就是 Rust 的 SonarLint,做静态分析、检查各种 idiom、发现潜在 bug,跑下面的命令:
cargo clippy我们也可以通过 clippy.toml 配置自己想要的规则。一般来说 IDE 插件会自动集成,不需要你手动跑。
最后看一个文件:rust-toolchain.toml。这个文件放在项目根目录,作用是锁定项目用的 Rust 版本:
[toolchain]
channel = "1.90.0"
targets = ["x86_64-unknown-linux-gnu"]
components = ["rustfmt", "clippy"]如果别人 clone 你的项目,本地没有 1.90.0,cargo 会自动下载安装。这个有点像 Java 项目里的 .sdkmanrc 或者 Maven 的 enforcer 插件,但更原生、更可靠。
好了,工具链就到这里。下面我们正式进入语言本身。
四、基础语法:跟 Java 大同小异
Rust 的语法表面上跟 C/Java 系还是比较像的,只不过 Rust 的类型放在变量名后面,主要原因应该还是能推导就推导,这样不用显式写类型。
变量定义用 let,默认不可变(跟 Java 反过来,Java 默认可变,要加 final 才不可变):
let x = 5;
x = 6; // 编译错误,因为 x 是不可变的
let mut y = 5; // 加 mut 表示可变
y = 6; // OK在 Java 中,我现在也喜欢用 var 关键字,让编译器自动做类型推导,个人觉得 Java 还是肯吸收别的语言的好东西的。
mut 这个关键字以后会反复出现,它就是"可变"的意思。为什么 Rust 要这么设计?简单说,Rust 希望你默认写出"少共享、少修改"的代码。变量能不改就不改,引用能只读就只读。后面讲并发时你会发现,这个习惯和 Rust 的安全模型是连在一起的。
Rust 还有一个 Java 没有的概念叫 shadowing,就是同名变量复用:
let x = 5;
let x = x + 1; // 这是一个新变量,跟原来的 x 没关系,只是名字一样
let x = "hello"; // 类型甚至可以变shadowing 在处理“同一个数据,类型变了”的场景特别有用。Java 里我们经常这样写:
String text = "123";
int value = Integer.parseInt(text);
int result = value + 1;这个代码很讨厌的就是,我们一直在取新的名字。Rust 允许你在同一条处理链上一直用 x 这个名字,对应类型可以变。这个东西刚开始看有点怪,用多了会觉得还挺顺。
数据类型这块,Rust 的整数类型比 Java 细:
i8, u8 // 有符号/无符号 8 位
i16, u16
i32, u32 // 默认整数类型
i64, u64
i128, u128
isize, usize // 跟平台位宽一致,用作下标的就是 usize
f32, f64 // 浮点,默认 f64
bool, char // 注意 char 是 4 字节的 Unicode 标量值,不是 ASCII 字符!Java 没有无符号整数类型,Rust 这里就完整多了。另外 char 这块,Java 的 char 是 2 字节、只能表示 BMP,Rust 的 char 直接是 4 字节,能塞下中文、emoji。
复合类型:
// 元组:异构
let tup: (i32, u32) = (100, 1);
let first = tup.0; // 通过 .0 .1 访问
// 数组:定长、同构
let a: [i32; 5] = [1, 2, 3, 4, 5];
let b = a[1]; // 越界访问会 panic(相当于 Java 抛 ArrayIndexOutOfBoundsException,但 Rust 用的是 panic 机制,不是受检异常)在 java 中,可以用 record 实现类似 tuple 的效果。
字面量这里有几个 Rust 特有的写法:
123_456 // 下划线分隔,可读性
0xff // 十六进制
0o123 // 八进制
0b11100 // 二进制
b'A' // 单字节字符(u8)
b"abc" // 字节字符串字面量,类型是 &[u8; 3],可以强转为 &[u8]函数定义:
fn plus_one(x: i32) -> i32 {
x + 1
}这里有个非常 Rust 特色的细节:函数最后一行不带分号,就是返回值。
fn main() {
let y = {
let x = 3;
x + 1 // 注意没分号,整个块的值是 4
};
println!("y = {y}");
}还有 {} 块本身就是表达式,上面这个例子里面 x + 1 就是这个块的返回值,赋给了 y。Java 里 {} 是语句块,没这个语义。
带分号的情况下,那一行就变成语句,值是 (),可以简单理解为 Java 的 void。所以下面这段就编译不过:
fn add(a: i32, b: i32) -> i32 {
a + b; // 错误,函数声明返回 i32,但这里返回了 ()
}if 在 Rust 里也是表达式(再次和 Java 不同):
let number = if condition { 5 } else { 6 };这种东西在 Java 里我们用三元运算符 condition ? 5 : 6 来表达。
循环用 loop、while、for,最好用的是 for:
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}常量用 const,跟 Java 的 static final 类似:必须显式指定类型,必须在编译期能确定值,不能用 mut:
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;全局变量用 static,跟 Java 的差不多,必须声明时初始化:
static G1: i32 = 10;
// 也可以 mut,但这样的话,读写都得用 unsafe(后面讲 unsafe)
static mut G2: i32 = 0;
unsafe {
G2 = 5;
}需要补充一句:static mut 在 Rust 2024 edition 已经被强烈不建议使用了,对它取引用会直接报错。如果真的需要共享可变全局状态,更推荐 Mutex、RwLock、OnceLock 这些类型,知道有这么个东西就行,先不深入。
跟 const 的区别:const 可能被编译器内联进每个使用点,static 就是个真实的内存地址。
注释用 // 或 /* */,跟 Java 一样。
到这里,跟 Java 大同小异的部分基本介绍完了。下面进入 Rust 的核心,也是 Java 程序员最不熟悉的部分。
五、Ownership:Rust 最有特色、也是最劝退的概念
Java 程序员一上来最容易被劝退的就是这块。我们慢慢来。
Java 是怎么管理内存的?
我们先回忆一下 Java。Java 的对象都在堆上,栈上只放引用:
User u1 = new User("javadoop");
User u2 = u1;这两行做的事,我们都很熟悉:堆上有一个 User 对象,栈上 u1 和 u2 这两个引用指向它。
栈上:
u1 ─┐
├──> 堆上的 User("javadoop")
u2 ─┘对象什么时候被回收?GC 决定。GC 通过可达性分析判断哪些对象没人引用了,然后回收它们的内存。
GC 的好处是开发者不用关心内存释放,写起来爽。坏处是:
- 有 STW,对延迟敏感的场景不友好
- 内存占用偏大
- 不够确定,你不知道一个对象什么时候真正被释放
所以 Java 程序员习惯了一个事实:引用可以随便复制,对象释放不用自己管。
但是 Rust 没有 GC,它也不像 C 那样让你 malloc/free,那样太容易出错。Rust 的方案是编译期就确定每个值什么时候被释放,靠的是一套叫所有权(ownership)的规则。
Rust 必须回答一个问题:一块堆内存,到底谁负责释放?
如果有多个变量都觉得自己"拥有"这块内存,那就麻烦了。释放一次,另一个变量就成了悬垂指针;释放两次,就是 double-free;都不释放,就是内存泄漏。Rust 的答案非常直接:一个值,在任意时刻只能有一个 owner。
三条规则,先背下来:
- Rust 中的每一个值都有一个所有者(owner)
- 值在任意时刻有且只有一个所有者
- 当所有者(变量)离开作用域,这个值就会被丢弃
是不是看起来还挺简单?我们看具体例子。
移动(move)
对基础类型,没什么好说的,直接拷贝:
let x = 5;
let y = x; // 栈上有两个 5,x 和 y 都能用但是对于 String 这种堆上分配的类型:
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}"); // 编译错误!s1 已经被 move 给 s2 了这里发生了什么?String 内部是一个 (指针, 长度, 容量) 的结构,let s2 = s1 这一行,从 Java 视角看就是一次浅拷贝(s1 和 s2 都指向同一块堆数据)。但 Rust 不允许两个变量同时拥有同一份堆数据(规则 2),所以它让 s1 失效,这个操作叫 move。
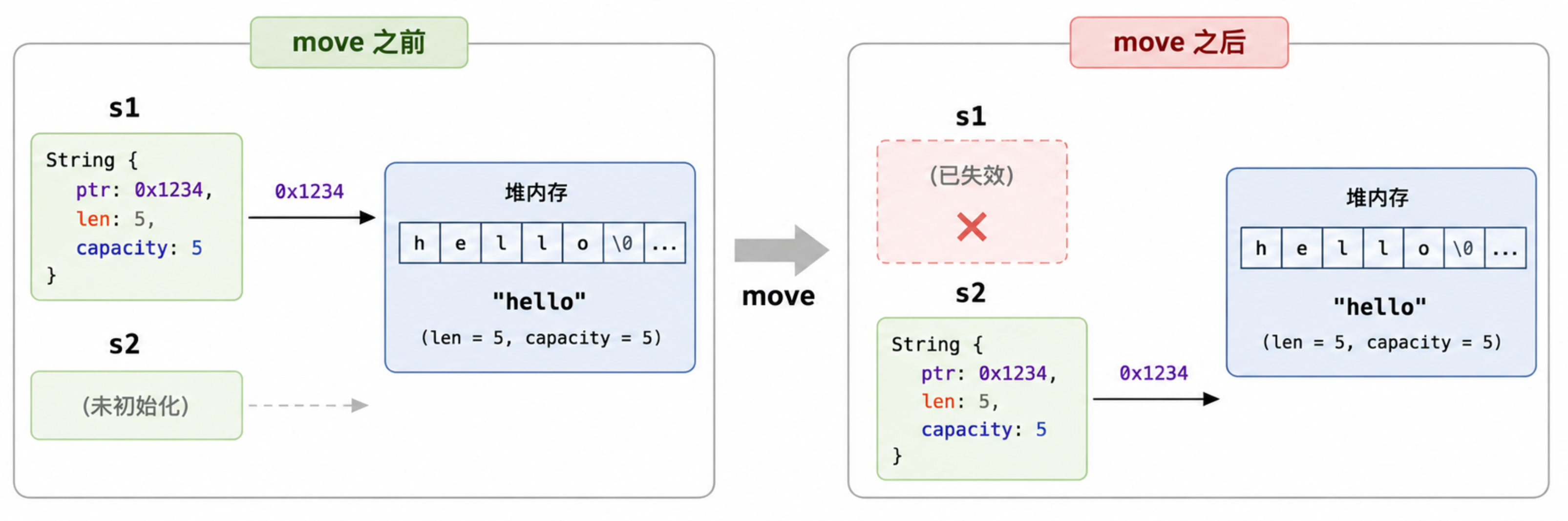
注意,这里堆上的 "hello" 没有复制一份,只是 owner 变了。
为什么要这么做?想象一下,如果 s1 和 s2 都指向同一块堆内存,s1 离开作用域时它要不要释放堆内存?如果释放了,s2 就指向了悬垂指针。如果不释放,那要靠谁来释放?这就是 C++ 里 double-free 问题的根源。Rust 通过"单一所有者"直接绕开了这个问题。
如果你真的想要两份独立的数据,用 clone:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("{s1} and {s2}"); // OK,s1 还能用这就是 Java 里的深拷贝。
Copy trait
那基础类型为什么不用 clone 也能继续用呢?因为它们实现了 Copy trait(先别管 trait 是什么,类似 Java 的接口),只要类型实现了 Copy,赋值操作就是在栈上的按位复制,不发生 move。
i32、bool、char、f64 这些基础类型都实现了 Copy。元组只要里面的元素都是 Copy,元组本身也是 Copy。
简单记几条:
i32、bool、char这类基础类型通常是Copy。String、Vec这类拥有堆内存的类型通常不是Copy。- 不是
Copy的类型,赋值、传参、返回值都可能发生 move。
引用和借用 borrow
每次都 move 来 move 去,写起来简直是噩梦。来看这段代码:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len();
(s, length) // 因为 s1 已经被 move 进函数了,所以得返回回去
}这种写法多多少少有点大病。我只是想知道字符串的长度,结果还得把字符串本身传出来再传回去。所以 Rust 提供了引用:
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1); // 传引用
println!("The length of '{}' is {}.", s1, len); // s1 还能用
}
fn calculate_length(s: &String) -> usize {
s.len()
}&s1 表示"我借给你 s1,但所有权还在我这里"。这个动作叫 borrow(借用),符号是 &。
简单类比:在 Java 里,方法参数传对象,本质就是传一个引用,方法内部可以访问对象,但对象的"主人"还是外面的代码。Rust 的引用大体上就是这个意思,只不过多了一层规则约束。
默认引用是不可变的。要修改,得用可变引用:
fn main() {
let mut s = String::from("hello");
change(&mut s); // 注意 mut 关键字到处都要写
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}可变引用这块,mut 写了两次,初学时很烦:
let mut s表示变量s可以被修改。&mut s表示把它以可变引用的方式借出去。
Rust 的借用规则可以用一句话概括:
同一时间,要么有任意多个不可变引用,要么只有一个可变引用,但不能同时有两者。
Rust 借用规则就是把这种事情提前拦住。只要有人在读,就不能同时拿一个可变引用去改;只要有人在改,就不能再让别人读或改。
多个只读引用可以:
let mut s = String::from("hello");
let r1 = &s; // 不可变引用
let r2 = &s; // 不可变引用,可以
println!("{r1}, {r2}");一个可变引用也可以:
let mut s = String::from("hello");
let r = &mut s;
r.push_str(", world");但是读写混在一起不行:
let mut s = String::from("hello");
let r1 = &s; // 不可变引用
let r2 = &mut s; // 编译错误!有不可变引用时不能要可变引用
println!("{r1}");两个可变引用也不行:
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s; // 编译错误!同时两个可变引用这个模型跟读写锁长得很像,但它不是运行时真的加了一把锁,它是编译器在检查引用关系。
引用的作用域是从声明开始到最后一次使用为止,叫做 NLL(Non-Lexical Lifetime):
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
println!("{r1} and {r2}"); // r1, r2 最后一次用在这里
let r3 = &mut s; // OK,因为 r1, r2 已经不再使用读到这里,所有权和借用的核心规则就讲完了。这部分初学的时候必然会跟编译器打架,习惯就好。Rust 编译器的报错信息写得相当友好,按提示改基本能过。
最后强调一点:借用检查全部是编译期完成的,运行时不会有任何额外开销,这是 Rust 一个非常重要的卖点。Java 那边为了实现线程安全,运行时要加各种锁、做各种 happens-before 同步,性能上是要付出代价的。Rust 把这些事情提前到编译期解决,运行时的代码就是干干净净的原生代码。
六、Struct:Rust 的"类"
Struct 就是 Rust 用来组织数据的方式,相当于 Java 的 class 但是只有字段没有方法。方法是在 impl 块里定义的。
定义和使用:
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
// 结构体更新语法,类似 Java 里 Lombok 的 @With
let user2 = User {
email: String::from("another@example.com"),
..user1 // 其余字段从 user1 取
};注意:..user1 这个操作可能会发生 move,比如 username 是 String,会被 move 到 user2,user1.username 之后就不能用了。
字段速记法(field init shorthand),跟 ES6 一样:
fn build_user(email: String, username: String) -> User {
User {
active: true,
username, // 等价于 username: username
email,
sign_in_count: 1,
}
}Rust 还有几种特殊的 struct:
// 元组结构体,没有字段名
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
// 单元结构体,没有任何字段,类比 Java 的标记类
struct AlwaysEqual;如果 struct 字段是引用,必须标注生命周期(后面讲),下面这个会报错:
struct User {
username: &str, // 编译错误:missing lifetime specifier
}因为 username 是引用类型,而我们没有给它标注生命周期。先知道有这么个东西就行,在介绍生命周期之前,我们先不要在 struct 上涉及引用,直接让 struct 拥有值。
方法和 self、&self、&mut self
Java 里方法跟字段都写在 class 里面,混在一起。Rust 不这么搞,数据放 struct,而方法放 impl 块里:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
let rect = Rectangle { width: 30, height: 50 };
rect.area();这里我们重点看一下 &self ,它是 Rust 方法签名里最关键的部分。
类比 Java:Java 方法里的 this 是个隐式参数,永远是一个引用,而且方法默认就能改字段。Rust 里的 self 是显式参数,并且分了三种形式:
self:拿走所有权(method 调用完就消费掉对象了)&self:不可变借用(最常用)&mut self:可变借用
struct Foo(i32);
impl Foo {
fn new() -> Self { // 没有 self,叫"关联函数",类比 Java 静态方法
Self(0)
}
fn consume(self) -> Self { // 拿走所有权,调用后原对象不能再用
Self(self.0 + 1)
}
fn get(&self) -> &i32 { // 不可变借用,最常见
&self.0
}
fn get_mut(&mut self) -> &mut i32 { // 可变借用,需要修改字段时用
&mut self.0
}
}调用方式:
let foo = Foo::new(); // 关联函数用 :: 调用
foo.get(); // 实例方法用 . 调用,自动加引用。它其实就是 (&foo).get()
Foo::get(&foo); // 等价写法,把实例方法当普通方法使用,只不过就是传一个实例进去&self 其实就是 self: &Self 的缩写,方法调用时编译器自动加 &。这跟 Java 的 this 自动传入是一个意思。
Java 里 this 永远是引用,方法默认就能改字段。Rust 把这件事拆开了:
- 只是读,就写
&self - 要改,就写
&mut self - 要消费整个对象,就写
self
我们看几个标准库的例子:
String::len(&self):只读取长度,用&selfString::push_str(&mut self, ...):在原字符串上追加,用&mut selfString::into_bytes(self):把 String 拆成Vec<u8>,原 String 没用了,用self
这个设计刚开始有点啰嗦,但它让 API 的意图非常清楚。你看到方法签名,就知道它会不会修改对象,会不会拿走对象。这是 Rust API 设计上一个非常贴心的地方。
跟 Java 不一样的还有一点,一个 struct 可以有多个 impl 块。比如你可以把方法按功能分到不同的 impl 块里,编译器最终会合并。
方法调用时 Rust 会自动引用和解引用,下面两个等价:
p1.distance(&p2);
(&p1).distance(&p2);关联函数(associated function)
不带 self 的就是关联函数,类比 Java 的 static 方法:
impl Rectangle {
fn square(size: u32) -> Self {
Self { width: size, height: size }
}
}
let r = Rectangle::square(10);String::from、Vec::new 这些都是关联函数。最常见的用途就是构造函数,但也可以是和这个类型相关的工具函数(比如 i32::from_str_radix,把字符串按指定进制解析成整数)。
打印结构体
Java 里我们重写 toString 来打印对象。Rust 这边我们用 Debug 或 Display trait(trait 后面讲,先认住语法):
#[derive(Debug)] // 自动派生 Debug
struct Rectangle {
width: u32,
height: u32,
}
let rect = Rectangle { width: 30, height: 50 };
println!("{rect:?}"); // Rectangle { width: 30, height: 50 }
println!("{rect:#?}"); // 多行展开,更清晰#[derive(...)] 是属性宏,类似 Lombok 的 @Data,自动给你生成代码。上面这种 :? 或者 :#? 使用的就是 Debug trait 的输出。
当然如果我们给 Rectangle 实现 Display trait,我们也可以这样:
use std::fmt;
impl fmt::Display for Rectangle {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "{} x {}", self.width, self.height)
}
}
println!("{}", rect); // 使用 Display trait 打印结构体
println!("{rect}"); // 或者这样写,它们是等价的七、Enum:比 Java 强大得多的枚举
Java 的 enum 你可以理解成"值就这几个的常量类"。Rust 的 enum 远不止于此,每个枚举变体可以带数据,而且数据形式可以不同。
enum Message {
Quit, // 不带数据
Move { x: i32, y: i32 }, // 带具名字段(像 struct)
Write(String), // 带一个 String
ChangeColor(i32, i32, i32), // 带元组
}是不是很强?这种 enum 在 Java 里只能用 sealed interface + record 来模拟(Java 17+),相当啰嗦:
sealed interface Message permits Quit, Move, Write, ChangeColor {}
record Quit() implements Message {}
record Move(int x, int y) implements Message {}
record Write(String text) implements Message {}
record ChangeColor(int r, int g, int b) implements Message {}enum 也可以加方法:
impl Message {
fn call(&self) {
// ...
}
}
let m = Message::Write(String::from("hello"));
m.call();Option:替代 null 的存在
Rust 没有 null。要表达"可能有值,可能没有",用 Option<T>:
enum Option<T> {
None,
Some(T),
}这跟 Java 的 Optional<T> 思路一样,但 Java 的问题是:就算用了 Optional,别人还是可以给你传 null,编译器是没有任何保证的。Rust 不一样,普通类型就是普通类型,Option<T> 就是可能为空的类型,二者在类型系统里分得很清楚。
这点对写代码的影响非常大。Java 里你看到:
User findUser(long id);你不知道它找不到时会怎么样:
- 返回 null?
- 抛异常?
- 返回一个空对象?
Rust 里如果可能找不到,签名通常会写成:
fn find_user(id: u64) -> Option<User>;这就很清楚了:调用方必须处理 None。
Option 是 prelude 里默认导入的,直接用:
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None; // 赋空值,类似 Java 中的 Integer absent_number = null;要拿出 Option 里的值,得用 match:
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1), // 解构里面的数据
}
}match:增强版 switch
match 大致对应 Java 的 switch,但更强:
- 必须穷尽所有可能(编译期检查)
- 可以解构(destructure)出数据
- 是表达式,可以赋值
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other), // 通配符,绑定到 other
// _ => ... // 不关心值时用 _
}Java 17 里加的 pattern matching 跟 Rust 思路相似,其实都是在借鉴 ML/Haskell/Scala 这些函数式语言的成熟设计,目前 Java 的完整度还差不少。
if let
只关心一个分支的时候,用 match 显得啰嗦:
let a = Some(10);
match a {
Some(v) => println!("v: {v}"), // 有值的时候进行打印
_ => (), // 没值的时候直接忽略
}这种情况用 if let 简化:
let a = Some(10);
if let Some(v) = a {
println!("v: {v}");
}if let 是 match 的语法糖,代价是放弃了穷尽性检查。带 else 分支也行:
if let Some(v) = a {
// ...
} else {
// ...
}while let 同理,常用于循环消费 Option:
while let Some(top) = stack.pop() {
println!("{top}");
}Result:替代异常的存在
前面我们说过,Rust 没有 Java 的 try/catch。可能失败的操作返回的是 Result<T, E>:
enum Result<T, E> {
Ok(T),
Err(E),
}Ok(T) 表示成功并带上结果,Err(E) 表示失败并带上错误信息。Result 跟 Option 思路完全一样,只不过 Option 不关心"为什么没值",Result 关心"失败的原因"。
举个例子,文件读取在 Java 里要么 throws IOException,要么调用方 try/catch:
String content = Files.readString(Path.of("hello.txt"));到 Rust 里,签名长这样:
fn read_to_string(path: &Path) -> Result<String, io::Error>;调用方必须处理 Result:
match std::fs::read_to_string("hello.txt") {
Ok(content) => println!("{content}"),
Err(e) => eprintln!("读取失败:{e}"),
}初学者肯定会觉得写 match 非常啰嗦,而且代码里面肯定有大量的 Option 和 Result,都这么写,会非常麻烦。所以 Rust 提供了 ? 操作符:
fn read_username() -> Result<String, io::Error> {
let content = std::fs::read_to_string("user.txt")?; // 出错就提前 return Err
Ok(content.trim().to_string())
}比如在 Result 上,? 后缀的语义是:拿到 Ok 就把值解包出来继续往下走,拿到 Err 就把错误直接 return 给调用方。自己不处理,交给上层处理,这相当于 Java 里的 throws 自动传播,只不过 Rust 把它做成了表达式级别的语法糖,而且必须显式标记每一处可能失败的调用,不会出现"忘了 catch"的情况。
当 ? 作用在 Option 上的时候,它的含义是"如果这个 Option 是 None 就直接 return None",思路一致。
八、Panic:不可恢复错误的兜底机制
前面我们讲了 Result,处理的是"调用方有机会救一下"的错误,比如文件没找到、网络超时、解析失败。但还有一类错误是真的没法救的,比如数组越界、整数除零。继续跑下去也没意义,Rust 用的是 panic 机制。
简单理解,panic 跟 Java 里"抛了个 RuntimeException 没人接,程序挂掉"差不多,但细节上有些区别。
什么时候会发生 panic
panic 主要分两类:显式触发,和运行时自动触发。
显式触发的就是直接调用 panic! 宏,或者调用了 Result/Option 上那些"出了错就 panic"的快捷方法:
panic!("出大事了"); // 显式 panic
let v: Vec<i32> = vec![1, 2, 3];
let x = v[100]; // 越界,自动 panic
let s: Option<i32> = None;
let n = s.unwrap(); // None 上 unwrap 会 panic
let n = s.expect("这里不应该是 None"); // 同 unwrap,但带自定义提示信息
todo!(); // 占位用,运行到这里就 panic,提醒你这部分还没写
unreachable!(); // 表达"这里逻辑上不可能执行到",万一执行到就 panicunwrap 和 expect 在写小工具或者快速验证想法的时候很方便,但正式代码里要小心,它们就是把 None/Err 直接转成 panic 的快捷方式。
运行时自动触发 panic 的常见场景,比如整数除零,或者数组、Vec、Slice 越界,这些都是运行的时候才会触发。
panic 发生后会怎么样
默认情况下,panic 会做这么几件事:
- 打印错误信息和文件位置到 stderr
- 沿着调用栈往上"展开"(unwinding),把每一层栈帧上的对象都按规则 Drop 掉,文件句柄会关、Mutex 锁会解、堆内存会释放
- 当前线程结束
注意第三点,是当前线程结束,不是整个进程。子线程 panic,主线程感知不到,除非主线程 join 它,会拿到一个 Err。但主线程 panic,整个进程就退出了。这点跟 Java 里 Thread 出现未捕获异常的行为类似。
panic 默认走 unwinding 是为了让析构函数能正常跑,但 unwinding 本身是有代价的:二进制会变大,性能也有点损耗。如果你不在乎这些,可以在 Cargo.toml 里改成 abort:
[profile.release]
panic = "abort"这样 panic 直接调用系统 abort,跳过 unwinding,二进制更小、跑得更快,但析构函数都不会执行。嵌入式或者对包体积敏感的场景常用这个。
想看完整调用栈,跑程序的时候带上环境变量:
RUST_BACKTRACE=1 cargo run # 简略 backtrace
RUST_BACKTRACE=full cargo run # 完整 backtraceResult 还是 panic:什么时候用哪个
Rust 官方有个挺清晰的指导原则:
- 调用方有可能合理处理的错误(文件没找到、网络超时、解析失败),返回 Result
- 程序不变量被打破、属于"代码 bug"的情况,直接 panic
举个例子,从用户输入解析数字,输入是不是数字调用方控制不了,应该返回 Result。而函数内部访问一个数组、且明确知道下标在范围内,万一越界那是代码 bug,让它 panic 就行。
实际写代码的几个习惯:
- 库代码尽量返回 Result,把"要不要 panic"的决定权交给调用方
- 应用代码可以适当
unwrap,但要用在能确认不会失败的地方 - 表达"这里逻辑上不可能执行到"用
unreachable!() - 还在写但没写完的代码用
todo!()占位,编译能过,运行时一执行就 panic
几个容易踩坑的点
第一个是整数溢出,前面提过一嘴,这里再展开说一下。debug 模式下溢出会 panic,release 模式下默认是回绕(wrap,比如 u8::MAX + 1 变成 0)。这意味着你在 debug 下跑得好好的代码,编译成 release 之后行为就完全不一样了,而且不会有任何提示。如果你需要明确的语义,用标准库提供的几个方法:
let a: u8 = 200;
let b = a.checked_add(100); // 返回 Option,溢出就是 None
let c = a.saturating_add(100); // 溢出就饱和到 u8::MAX
let d = a.wrapping_add(100); // 显式回绕
let (e, overflowed) = a.overflowing_add(100); // 返回结果和是否溢出第二个是 panic 不要随便穿过 FFI 边界。Rust 代码如果通过 C ABI 被外部调用,让 panic 直接展开到 C 那一侧是 undefined behavior。这种场景需要用 std::panic::catch_unwind 把 panic 接住、转成错误码返回:
use std::panic;
let result = panic::catch_unwind(|| {
panic!("oops");
});
match result {
Ok(_) => println!("正常返回"),
Err(_) => println!("接住了一个 panic"),
}注意,catch_unwind 不是 Java 的 try/catch,它只是给 FFI 边界用的安全网。日常的错误处理还是 Result + ?,不要拿 catch_unwind 当 try/catch 来滥用。而且如果你设了 panic = "abort",catch_unwind 也根本接不住。所以,我们最好不要用 Java 的思维,老想着用 try/catch,而是应该始终使用 Result 来显式传播。
到这里 panic 就介绍完了。一句话总结:Result 处理"可能失败的事情",panic 处理"出 bug 了的事情",二者分工明确,不要混用。
九、集合
集合这块对 Java 程序员来说不算特别陌生,HashMap、ArrayList 这些东西的概念是通用的,差别主要在 API 风格和所有权处理上。我们挑几个常用的过一下。
Vec:对应 Java 的 ArrayList
Vec<T> 就是 Rust 的动态数组,对应 Java 的 ArrayList<T>,用法上没啥惊喜:
let v: Vec<i32> = Vec::new(); // 空 Vec
let v = vec![1, 2, 3]; // 用宏初始化,最常用
let mut v = Vec::with_capacity(10); // 预分配容量,类似 new ArrayList<>(10)增删改查这些基本操作:
let mut v = vec![1, 2, 3];
v.push(4); // 尾部添加
v.pop(); // 弹出最后一个,返回 Option<T>
v.insert(0, 99); // 在指定下标插入
v.remove(0); // 删除指定下标
let first = &v[0]; // 索引访问,越界会 panic
let first = v.get(0); // 安全访问,返回 Option<&T>注意 v[0] 和 v.get(0) 的区别。v[0] 越界会直接 panic,v.get(0) 越界会返回 None。这种"同一个操作给两个 API,一个出事就崩,一个出事返回 Option"的设计在 Rust 标准库里非常常见,后面 HashMap、String 都能看到。
迭代有三种姿势,这是 Rust 比 Java 灵活的地方:
let v = vec![1, 2, 3];
// 1. 不可变借用,最常用
for x in &v {
println!("{x}");
}
// 2. 可变借用,可以修改元素
let mut v = vec![1, 2, 3];
for x in &mut v {
*x += 10; // 通过解引用来修改
}
// 3. 拿走所有权,迭代完 v 就不能再用了
for x in v {
println!("{x}");
}这三种迭代方式分别对应方法 iter()、iter_mut()、into_iter(),是后面讲迭代器时会反复见到的三件套,先有个印象就行。
Vec 还有一堆函数式风格的链式方法,这块在 Java 里要靠 Stream API 才能写得这么顺:
let v = vec![1, 2, 3, 4, 5];
let sum: i32 = v.iter().filter(|&&x| x > 2).map(|x| x * 2).sum();
// 类似 Java: v.stream().filter(x -> x > 2).mapToInt(x -> x * 2).sum()这里 |&&x| 那两个 & 看着很怪,先不用纠结,后面讲闭包和迭代器时会展开,跟着代码先有个感觉就行。
迭代器是 Rust 里非常重要的一个话题,展开讲会跑偏,这里就先到这。
HashMap:用法跟 Java 几乎一样
HashMap<K, V> 用法上跟 Java 的 HashMap 没啥本质区别,先看基础操作:
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
// 遍历
for (key, value) in &scores {
println!("{key}: {value}");
}
// 更新就是直接覆盖
scores.insert(String::from("Blue"), 25);注意 HashMap 不在 prelude 里,要手动 use std::collections::HashMap,这点跟 Vec 不一样。
HashMap 的 insert 需要所有权,因为 insert 以后,对象归 HashMap 所有了。它的 get 操作要单独说一下。Java 里我们写 map.get(key) 拿到的就是 V 本身(要么是值,要么是 null),一步到位。Rust 这边写起来要绕几道弯,初学的时候很容易被绕晕,我们一步步来看。
第一层,最朴素的写法:
let v = scores.get("Blue");这里 v 的类型是 Option<&i32>。看着挺唬人,拆开来其实就两件事:
- 外层
Option<...>:因为 key 不一定存在,找不到时返回None,找到了返回Some(...)。Rust 没有 null,所有"可能没有"的情况都用Option表达。 - 内层
&i32而不是i32:因为 value 是 HashMap 拥有的,get只是借给你看一眼,不会把所有权交出去。这跟我们前面讲的借用规则是一致的,能借就借,少做不必要的复制。
要拿到真正可以参与运算的 i32,得把这两层都剥掉。最朴实的写法就是 match:
let v: i32 = match scores.get("Blue") {
Some(&n) => n, // 模式里写 &n,把外层 Option 和内层引用一起解掉,n 是 i32
None => 0, // 找不到给个默认值
};每次都写 match 太啰嗦,标准库给了一组组合子方法,可以链式地把这两层处理掉。我们一层层往下加:
// 第二层:把内层 &i32 复制成 i32,但外层 Option 还在,得到 Option<i32>
let v: Option<i32> = scores.get("Blue").copied();
// 第三层:再给个默认值,把外层 Option 也剥掉,得到 i32
let v: i32 = scores.get("Blue").copied().unwrap_or(0);
// 或者:确信有值就直接 unwrap,找不到就 panic
let v: i32 = scores.get("Blue").copied().unwrap();每加一步,类型就变一次,目标都是把 Option<&i32> 一步步剥成最终想要的 i32。
copied 这里要解释一下。它的作用是把 Option<&T> 变成 Option<T>,前提是 T 实现了 Copy(i32、bool 这种基础类型都实现了)。如果 value 是 String 这种非 Copy 类型,对应的方法叫 cloned,做一次深拷贝。注意一个是 copied 一个是 cloned。
let mut names: HashMap<i32, String> = HashMap::new();
names.insert(1, String::from("javadoop"));
let n: Option<String> = names.get(&1).cloned();如果不想付出 clone 的代价,那就一直在引用层面操作,不剥内层:
let n: Option<&String> = names.get(&1);
if let Some(name) = n {
println!("name: {name}"); // name 是 &String,println 会自动处理
}刚开始写 Rust 看到这种 .copied().unwrap_or(0) 的链式调用会觉得啰嗦,写多了会发现这种"按需剥皮"的设计其实挺优雅,每一步剥的是什么、付出什么代价,都写得清清楚楚。Java 那边一个 map.get(key) 把所有事情都打包了,方便是方便,但是 null 检查、类型装箱拆箱这些事也都被藏起来了。
下面介绍一个 Rust 中非常好用的 entry API。在 Java 中,我们经常会见到这种代码:
Integer count = map.get(key);
if (count == null) {
map.put(key, 1);
} else {
map.put(key, count + 1);
}JDK 8 以后可以用 map.merge 或者 computeIfAbsent 来实现类似的需求,但这些方法各管一摊,没有形成一套统一的 API。Rust 这边官方就提供了一套统一的 entry API,把"查找 + 判断 + 插入/更新"这种组合操作打包成了原子操作:
// "如果不存在就插入"
scores.entry(String::from("Blue")).or_insert(50);
// "存在就 +1,不存在就插入 1",统计词频经典写法
let text = "hello world hello";
let mut map = HashMap::new();
for word in text.split_whitespace() {
*map.entry(word).or_insert(0) += 1;
}
// 这里 or_insert 返回的是 &mut V,所以 *xxx += 1 就是直接在 map 里改第二个写法第一次看可能有点绕,但用熟了非常顺手,在 Rust 代码里随处可见。
再强调一下,HashMap 的所有权这块要稍微注意一下:
let key = String::from("hello");
let val = String::from("world");
let mut map = HashMap::new();
map.insert(key, val);
// 此时 key 和 val 都被 move 进 map 了,外面不能再用如果不想 move,那就插入 clone 出来的副本,或者用引用作为 key/value(涉及生命周期,先不展开)。
其他集合简单过一下
标准库里 std::collections 下还有这些,跟 Java 基本能一一对上:
HashSet<T>:哈希集合,对应 Java 的 HashSetBTreeMap<K, V>:基于 B 树的有序 Map,对应 Java 的 TreeMapBTreeSet<T>:有序 Set,对应 Java 的 TreeSetVecDeque<T>:基于环形缓冲区的双端队列,对应 Java 的 ArrayDequeLinkedList<T>:双向链表,跟 Java 一样标准库里有,但用得很少
用法跟你想的差不多,需要的时候查一下文档就行,这里就不展开了。
集合就讲到这。下一节我们专门聊聊字符串,按理说字符串也算一种集合,The Rust Book 也是把它放在 collections 章节里的,但 Rust 的 String 和 &str 区分本质上是所有权设计的体现,跟集合不是一个维度的事情,单独拉出来讲会更清楚一些。
十、字符串:String 和 &str
Rust 里跟字符串相关的核心类型有两个:String 和 &str,它们的关系大概是这样的:
String:拥有所有权的可变字符串,数据存在堆上,概念上接近 Java 的StringBuilder&str:字符串切片(slice),是对一段字符串数据的不可变借用
Java 里只有一个 String(再加上可变的 StringBuilder),你不需要在两个类型之间做选择。Rust 这里硬是把"字符串数据本身"和"对字符串数据的借用"分成了两个类型。
我们先看几个例子建立感觉:
let s1: &str = "hello"; // 字符串字面量是 &'static str
let s2: String = String::from("hello"); // 拥有所有权的 String
let s3: &str = &s2; // 从 String 借出 &str
let s4: &str = &s2[0..3]; // 切片,"hel"字符串字面量 "hello" 的类型是 &'static str,它是写死在程序二进制里的一段 UTF-8 数据,整个程序运行期间都存在(这就是 'static 生命周期,后面讲生命周期的时候我们再仔细聊)。
为什么 Rust 要把字符串拆成两个类型?其实回想一下我们前面讲的所有权,这个事情就比较好理解了:
- 字面量是写死在二进制里的,没人"拥有"它,自然只能借用
- 你自己 new 出来的字符串,得有个 owner 来负责释放,所以是
String - 函数参数大部分时候只是想读字符串内容,没必要拿走所有权,那就用
&str
第三点特别重要。我们看这两个写法:
fn greet(name: String) { /* ... */ } // 拿走所有权,调用方传完就不能用了
fn greet(name: &str) { /* ... */ } // 借用,调用方还能继续用绝大多数时候我们应该写成 &str,因为它兼容性最好,传 &String 会被自动转成 &str,传字面量 "abc" 也行。这是 Rust 一个非常通用的 API 设计习惯:入参用 &str,返回值用 String。
类型转换我们看一下,主要也就这几种:
let s: String = "hello".to_string(); // &str -> String
let s: String = String::from("hello"); // 同上
let s: String = "hello".to_owned(); // 同上,更通用一点的写法
let r: &str = &s; // String -> &str,自动 deref
let r: &str = s.as_str(); // 同上,显式写法to_string、to_owned、String::from 三种写法效果都一样,看个人习惯。
接下来看 String 的常用操作:
let mut s = String::from("hello");
s.push_str(", world"); // 追加 &str
s.push('!'); // 追加单个 char
s += " 又来"; // 重载了 += 运算符
let s2 = format!("{} - {}", s, 42); // 类似 Java 的 String.format,最常用的拼接方式format! 是 Rust 里最常用的字符串格式化方式,跟 println! 用法一样,只不过返回 String 而不是打印。
下面讲一个跟 Java 差异很大的点:UTF-8。
Rust 的 String 在底层就是一个 Vec<u8>,存的是 UTF-8 编码的字节。这跟 Java 的 String 不一样,Java 的 String 早期是 UTF-16,JDK 9 之后引入了 Compact Strings(ASCII 部分用 byte 存),但对外暴露的 char API 还是 UTF-16 code unit。
这个差异带来一个大坑:Rust 的 String 不能用整数下标访问字符。
let s = String::from("你好");
let c = s[0]; // 编译错误! String 没有实现 Index<usize>为啥不让索引?因为 UTF-8 是变长编码,中文字符"你"占 3 个字节,如果允许 s[0],那拿到的是第一个字节(不完整字符),这种 API 太容易出错,Rust 干脆不提供。
要遍历字符,用 chars():
let s = String::from("你好 hello");
for c in s.chars() {
println!("{c}"); // 一次一个 char,Rust 的 char 是 4 字节 Unicode 标量值
}
for b in s.bytes() {
println!("{b}"); // 一次一个字节
}要切片,可以按字节范围切,但范围必须落在字符边界上,否则运行时 panic:
let s = String::from("你好");
let slice = &s[0..3]; // OK,"你" 占 3 个字节
let slice = &s[0..1]; // 运行时 panic! 1 不是字符边界写多了就习惯了,简单说就是:需要按字符处理就用 chars(),需要按字节处理就用 bytes(),少直接用下标切。如果非得按字符位置切,可以用 s.char_indices() 拿到每个字符对应的字节起点。
Rust 的字符串 API 比 Java 啰嗦很多,但安全性和明确性也好很多,这是它一贯的取舍。
最后多说一句:String 和 &str 这种区分,其实是 Rust 设计的一个缩影,体现了"所有权 vs 借用"对 API 设计的影响。这种"同一个东西分成 owned 和 borrowed 两个类型"的模式,在标准库里到处都是,比如 PathBuf / &Path、Vec<T> / &[T]、OsString / &OsStr 等等。看到这种结对的类型,知道就是这个道理就行。
十一、泛型与 Trait:Rust 的抽象机制
讲完字符串,我们终于要面对前面欠了一路的债:trait。Copy 是 trait、Debug 是 trait、Display 也是 trait,#[derive(Debug)] 干的事就是自动给你的 struct 实现 Debug 这个 trait。这一节我们把这些零碎认知串起来,而且 trait 离不开泛型,所以我们一起讲。
泛型函数:和 Java 长得几乎一样
我们先看泛型函数。Java 里写一个返回数组第一个元素的方法:
public <T> T first(T[] arr) {
return arr[0];
}Rust 里:
fn first<T>(list: &[T]) -> &T {
&list[0]
}<T> 这个写法跟 Java 一模一样,T 是类型参数,调用时编译器会做类型推导。注意 Rust 这里返回的是 &T,因为我们只是想看一眼,不想拿走所有权(前面所有权那一节讲过的逻辑)。
泛型 struct 和 enum
struct 也可以是泛型的:
struct Point<T> {
x: T,
y: T,
}
let int_point = Point { x: 5, y: 10 };
let float_point = Point { x: 1.0, y: 4.0 };不同字段还可以用不同的泛型参数:
struct Pair<T, U> {
first: T,
second: U,
}enum 也一样,前面我们见过的 Option<T> 和 Result<T, E> 就是泛型 enum:
enum Option<T> {
None,
Some(T),
}
enum Result<T, E> {
Ok(T),
Err(E),
}是不是看起来都很眼熟?这部分跟 Java 思路完全一致。
单态化:Rust 泛型和 Java 泛型的本质差别
但这里要专门说一下 Rust 泛型在底层的实现,这是 Rust 跟 Java 一个很本质的差别。
Java 的泛型大家都知道,是类型擦除:编译期帮你做类型检查,编译完了泛型信息就没了,所以说 Java 的泛型更像是语法糖,运行时统一是 Object。这就是为什么 Java 里你不能 new T()、不能 T.class,泛型方法也没法重载只在泛型参数上不同的版本。
Rust 不是这样,Rust 用的叫单态化(monomorphization):编译期看到你用了哪些具体类型,就给每种类型生成一份代码。比如:
let a = Some(5_i32);
let b = Some("hello");编译之后,相当于编译器帮你生成了两份代码:
// 大致是这个意思,伪代码
enum Option_i32 { None, Some(i32) }
enum Option_str { None, Some(&'static str) }这就是为什么 Rust 泛型在运行时没有任何性能损失,它编译完根本就没有泛型,全是具体类型,跟你手写一份一份的代码效果一样。代价是二进制可能会变大(每个具体类型一份代码),但运行时是真的快。
Java 的泛型擦除是为了向后兼容,JDK 5 引入泛型时不能破坏已有的字节码。Rust 没有这个历史包袱,从一开始就是单态化。
Rust 的泛型使用上和 Java 几乎没什么差别,还是非常简单的。
Trait:Rust 的"接口"
trait 你可以先粗暴地理解成 Java 的 interface,它定义一组行为,类型可以选择实现这些行为:
trait Greet {
fn hello(&self);
}
struct English;
struct Chinese;
impl Greet for English {
fn hello(&self) {
println!("Hello!");
}
}
impl Greet for Chinese {
fn hello(&self) {
println!("你好!");
}
}这跟 Java 的 interface 思路上几乎一样,只不过语法上有个非常关键的差别:
- Java 里实现 interface 是写在类定义那里的(
class English implements Greet) - Rust 里实现 trait 是单独写一个
impl Trait for Type块,跟类型定义是分开的
这个差别很重要,因为它意味着你可以给已经存在的类型实现新的 trait。比如你想给 i32 加点新方法:
trait Double {
fn double(&self) -> Self;
}
impl Double for i32 {
fn double(&self) -> Self {
self * 2
}
}
let x = 5_i32;
let y = x.double(); // 10是不是很爽?Java 里要做这种事只能写工具类的 static 方法,永远没法写成 5.double() 这种调用形式。Kotlin 里的扩展函数其实就是借鉴自这种模式。
默认方法
跟 Java 8 之后的 default method 一样,trait 里也可以提供默认实现:
trait Greet {
fn hello(&self) {
println!("Hi there!"); // 默认实现
}
}
struct Anonymous;
impl Greet for Anonymous {} // 啥也不写,用默认实现
Anonymous.hello(); // 输出 Hi there!实现的时候不写就用默认的,写了就覆盖默认实现,跟 Java 一模一样。
孤儿规则
上面我们说"可以给已有类型实现新 trait",但这里有个很重要的限制,叫孤儿规则(orphan rule):
trait 或者类型,必须有一个是你自己 crate 里定义的,你才能写
impl Trait for Type。
也就是说:
- 可以给你自己的 struct 实现别人的 trait(比如 Display)
- 可以给别人的类型实现你自己的 trait
- 不可以给别人的类型实现别人的 trait
为什么要这么限制?想象一下,如果你能给 Vec<T> 实现 Display,我也能给 Vec<T> 实现 Display,那两份代码同时存在就冲突了,编译器也不知道用谁的。孤儿规则就是为了避免这种冲突。
绕过孤儿规则的常见做法是用 newtype 模式包一层:
struct MyVec(Vec<i32>); // 用一个 tuple struct 包一下,这就是我自己的类型了
impl std::fmt::Display for MyVec {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
// ...
Ok(())
}
}Trait Bound:泛型 + trait
讲到这里,我们可以把泛型和 trait 串起来了,其实对于 Java 开发者来说,这也不是什么新鲜东西。
我们前面写过这个函数:
fn first<T>(list: &[T]) -> &T {
&list[0]
}这个能编译。但如果我们想找最大值呢?
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest { // 编译错误!T 未必能比较
largest = item;
}
}
largest
}这就编译不过了。因为 T 是任意类型,编译器不知道它能不能用 > 比较。
我们得告诉编译器:T 必须实现某个能比较大小的 trait。这就是 trait bound:
fn largest<T: PartialOrd>(list: &[T]) -> &T {
// ...
}T: PartialOrd 的意思是"T 必须实现 PartialOrd 这个 trait"。PartialOrd 是标准库里定义"能不能比较大小"的 trait。
这个跟 Java 里的 <T extends Comparable<T>> 是一个意思,只不过 Rust 用 : 不用 extends。
多个 bound 用 + 连接:
use std::fmt::Display;
fn print_and_compare<T: PartialOrd + Display>(a: T, b: T) {
// T 必须既能比较,又能用 Display 打印
}bound 一多,写在 <> 里太挤,可以用 where 子句拉到后面:
fn complex<T, U>(a: T, b: U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
// ...
}where 子句完全等价于写在 <> 里的形式,纯粹是为了可读性,两种代码我们都很常见。
标准库里常见的 trait
Rust 标准库里有一堆"基础设施"级别的 trait,写代码经常会碰到。我们挑最常见的过一下:
Debug:调试用打印,对应{:?},前面 struct 那节讲过Display:用户可见的打印,对应{},需要手动实现Clone:深拷贝,对应.clone()方法Copy:按位复制,前面所有权那节讲过PartialEq/Eq:相等比较,对应==PartialOrd/Ord:大小比较,对应<>Default:提供默认值,调用T::default(),这里的默认值类似 Java 中的零值Hash:哈希计算,作为 HashMap 的 key 必须实现From/Into:类型转换,下面单独说
为什么 PartialEq 和 Eq 要分两个?因为浮点数有 NaN,NaN != NaN,没法满足完整等价关系,所以浮点数只实现 PartialEq 不实现 Eq。PartialOrd 和 Ord 同理,浮点数只实现前者。这种"完整版和残缺版"的成对设计在 Rust 里很常见,反映的是数学意义上严格不严格的差别。
这些 trait 大部分可以用 #[derive(...)] 自动派生:
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
struct User {
name: String,
age: u32,
}这相当于 Java 里 Lombok 的 @Data 之类的注解。一个 struct 上挂一串 derive 是非常常见的写法。
From 和 Into
From 和 Into 这一对 trait 用得特别多,专门讲一下,它们做类型转换,类似 Java 中的 Converter,把一个对象转换成另一个对象:
let s: String = String::from("hello"); // 用 From
let s: String = "hello".into(); // 用 Into这两个写法效果一样。规则是:你只要给类型实现了 From,编译器自动给你来一份对应的 Into,不用自己写:
impl From<&str> for String { /* 标准库实现 */ }
// 编译器自动推导出:
// impl Into<String> for &str { /* ... */ }所以写代码的时候,实现就实现 From,调用就尽量用 Into,灵活性最高。
? 操作符里也用了 From,做错误类型自动转换。比如你的函数返回 Result<T, MyError>,里面调用了一个返回 Result<T, io::Error> 的函数,只要 MyError 实现了 From<io::Error>,? 就能自动帮你把 io::Error 转成 MyError:
impl From<io::Error> for MyError {
fn from(e: io::Error) -> Self { /* ... */ }
}
fn read() -> Result<String, MyError> {
let s = std::fs::read_to_string("a.txt")?; // io::Error 自动转成 MyError
Ok(s)
}这个特性让自定义错误类型用起来非常顺手,是 Rust 错误处理生态非常重要的一块。日常项目里大家一般会用 thiserror 这个库帮你自动生成这些 From 实现,更省事,这里先不展开。
静态分发 vs 动态分发:impl Trait 和 dyn Trait
最后我们来聊一个 Rust 跟 Java 差别非常大的点:多态怎么实现。
Java 里多态就一种方式,运行时动态分发。你写 List<String>,运行时根据具体类型(ArrayList 还是 LinkedList)查虚表(vtable)找方法,这个开销虽然小,但是有的。
Rust 提供了两种方式,写起来不一样,运行时行为也不一样。
第一种,impl Trait,静态分发:
fn greet(g: impl Greet) {
g.hello();
}这里参数类型写的是 impl Greet,意思是"任何实现了 Greet 的类型"。编译时编译器看到你传了 English,就给你生成一份 greet_for_English 的代码;传了 Chinese,再生成一份 greet_for_Chinese。这就是单态化的应用,运行时没有查表,没有性能损失。
impl Trait 等价于泛型,对于 Java 开发者来说,会更喜欢用泛型,下面这两个写法效果是一样的:
fn greet(g: impl Greet) { /* ... */ }
fn greet<T: Greet>(g: T) { /* ... */ }第二种,dyn Trait,动态分发:
fn greet(g: &dyn Greet) {
g.hello();
}dyn Greet 表示"某个实现了 Greet 的类型,但具体是啥到运行时才知道"。这个就跟 Java 的 interface 引用就很像了,运行时通过虚表找方法。
为什么前面要加 &?因为 dyn Trait 是 unsized 的,不同具体类型大小不一样,编译器没法在栈上给它分配固定大小,只能通过指针来访问。这点 Java 程序员可能不太直观,因为 Java 里所有对象引用大小都一样(都是 8 字节的引用),不存在这个问题。
后面讲智能指针那一节我们会看到,除了 &,还有别的指针类型也能包住 dyn Trait,原理一样。这里先用最简单的 & 就够了。
什么时候用哪个?经验法则:
- 同质集合(一个 Vec 里的元素都是同一个具体类型)→ 用
impl Trait/ 泛型 - 异质集合(一个 Vec 里要装不同的具体类型)→ 用
&dyn Trait
举个例子:
// 异质集合:必须用 dyn
let english = English;
let chinese = Chinese;
let greeters: Vec<&dyn Greet> = vec![&english, &chinese];
for g in &greeters {
g.hello();
}这种情况就只能用 dyn,因为 Vec 要求所有元素大小一致,但是这里要往 Vec 里面塞两个不同的类型,使用泛型的版本肯定编译不过。
简单总结:默认用 impl Trait / 泛型,性能最好,这也是大多数情况;只有当你确实需要"在一个集合里装不同具体类型"的时候,才退而求其次用 dyn Trait。
关联类型
最后再补充一个挺重要的概念:关联类型(associated type)。
关联类型说白了就是 trait 里面声明的一个"类型占位符",让实现这个 trait 的类型自己来填。最经典的例子就是 Iterator:
pub trait Iterator {
type Item; // 关联类型,每个迭代器自己说"我吐出来的元素是啥类型"
fn next(&mut self) -> Option<Self::Item>;
}这里的 type Item 就是关联类型。每个实现 Iterator 的类型,自己定下 Item 是啥:
struct Counter { count: u32 }
impl Iterator for Counter {
type Item = u32; // 我这个迭代器吐的是 u32
fn next(&mut self) -> Option<u32> {
self.count += 1;
Some(self.count)
}
}读到这里大家可能会犯嘀咕:这跟泛型有啥区别?我直接写成 trait Iterator<T> 不也一样吗?
我们拿标准库里两个 trait 对比一下就清楚了。From 用的是泛型参数,Iterator 用的是关联类型,为啥选了不同的方式?
先看 From:
pub trait From<T> {
fn from(value: T) -> Self;
}为啥 From 用泛型?因为同一个类型可以从很多种其他类型转换过来。比如 String,很多其他的类型都可以转换成 String:
impl From<&str> for String { /* ... */ }
impl From<char> for String { /* ... */ }注意,是同一个 String,给 From 实现了多次,每次 T 不一样。这种"一个类型对一个 trait 可以多次实现",正是泛型参数的特点。这里你可以理解为,From<&str> 和 From<char> 在编译器眼里就是两个不同的 trait,所以同一个类型分别实现这两个 trait 是没问题的。
再看 Iterator。反过来想一下,假设硬把它写成 trait Iterator<T>,那就允许给 Counter 同时写 impl Iterator<u32> 和 impl Iterator<String> 两份实现,会发生什么?
let mut c = Counter { count: 0 };
c.next(); // 编译器懵了:你要哪个 next?u32 那个还是 String 那个?调用方就得每次显式标类型参数才能消歧义,非常难受。但其实仔细想想,"一个迭代器同时能吐 u32 又能吐 String"这种事根本不符合迭代器的语义。一个具体的迭代器,元素类型就该是固定的,只该实现一次。关联类型就是把"每个实现者只能填一种类型"这个约束写进了 trait 定义里,从源头避免了上面那种歧义。
所以选哪种,看的就是这个:
- 同一个类型可以"自然地"实现这个 trait 多次(每次类型参数不同)→ 用泛型参数,代表:
From<T>、Add<Rhs> - 同一个类型对这个 trait 只该有一种实现 → 用关联类型,代表:
Iterator、Deref
调用方约束关联类型的语法长这样:
fn sum<I: Iterator<Item = i32>>(iter: I) -> i32 { /* ... */ }Item = i32 意思是"我要的迭代器,它的 Item 必须是 i32"。日常代码里这种写法见得非常多。
先把这个概念建立起来就够了,剩下的等真用到再深究。
到这里 trait 和泛型的核心内容就讲完了。我们还跳过了一些东西,比如 trait 对象的安全性(object safety)等,留给读者自己慢慢探索。这一节的目标是先建立起整体认知,能看懂代码、能写常见的代码就够了。
十二、生命周期:让借用规则自洽的最后一块拼图
前面所有权那一节我们讲过引用:&s 把值借出去,所有者还在外面。当时为了让大家先建立直觉,我们故意没提一个东西:生命周期(lifetime)。这一节就是要把这个坑填上。
生命周期可能是 Rust 里最让人懵的概念之一,但它要解决的问题其实很简单,甚至大部分时候我们可以不用关心。
为什么需要生命周期?
先看一段代码:
fn main() {
let r; // 1. 声明 r
{
let x = 5;
r = &x; // 2. 让 r 指向 x
} // 3. x 在这里被销毁
println!("r: {r}"); // 4. 用 r —— 但 x 已经不存在了!
}这段代码在 C/C++ 里会编译过去,运行时拿到一个悬垂指针,行为就完全不可预期了。在 Java 里这个问题不存在,因为只要还有引用指向 x,GC 就不会回收 x。
Rust 既没有 GC,又允许引用,怎么办?答案就是生命周期。
Rust 编译器有个组件叫借用检查器(borrow checker),它的工作就是检查每个引用的"存活期"是不是落在被引用对象的"存活期"以内。上面这段代码,借用检查器一看就发现:r 想活到 println! 那行,但它指向的 x 在内层大括号结束就死了。这种引用 Rust 是不允许存在的,编译器直接报错。
所以记住一个核心原则:
引用的存活时间不能超过它所指向的值。
这个原则在大部分简单代码里编译器自己就能推导出来,我们感觉不到生命周期的存在。但有些场景编译器推导不出来,就需要我们手动标注。
生命周期标注的基本语法
生命周期标注用一个撇号加一个名字,比如 'a、'b、'static:
&i32 // 普通引用
&'a i32 // 带生命周期标注的引用,表示这个引用活在 'a 这个范围里
&'a mut i32 // 带生命周期标注的可变引用'a 这个名字本身没啥含义,就跟泛型参数 T 一样,是个占位符。读的时候 'a 念作 "tick a"。
光看语法没啥意义,我们看它在哪儿用。
函数签名里的生命周期
经典例子:写一个函数,返回两个字符串切片中比较长的那个。
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}这段代码看起来人畜无害,但是编译不过:
error[E0106]: missing lifetime specifier为啥?因为编译器需要知道:返回的 &str 是一个借用,但是到底是借自 x 还是借自 y?这两个的生命周期可能不一样,调用方收到这个返回值,能用多久,编译器算不出来。
我们来标注:
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}这段标注的意思是:x、y 和返回值这三者共享同一个生命周期 'a。具体说就是:返回值的生命周期,是 x 和 y 中较短的那个。
这个怎么用呢?看例子:
let s1 = String::from("long string");
let result;
{
let s2 = String::from("short");
result = longest(s1.as_str(), s2.as_str());
println!("{result}"); // 在这里用 result,s2 还活着,OK
}
// println!("{result}"); // 这里就不行了,s2 已经死了,编译错误注意一点:生命周期标注不会真的改变值的存活时间,它只是给编译器的描述,告诉编译器"这几个引用应该满足什么样的关系"。如果你描述的关系不成立,编译器会报错;但加了标注本身不会让对象多活一会儿。
类比 Java:Java 的泛型 <T> 是描述类型的关系,不会真的造出新类型来。Rust 的 <'a> 也是同样的角色,描述生命周期之间的关系。
Struct 里的引用:必须标注生命周期
Struct 那一节我们说过,如果 struct 字段是引用,必须标注生命周期,当时跳过了。现在补上:
struct Excerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let excerpt = Excerpt { part: first_sentence };
println!("{}", excerpt.part);
}Excerpt<'a> 的意思是:这个 struct 持有一个引用,引用的生命周期是 'a,而 struct 实例本身的存活时间不能超过 'a。说白了就是,excerpt 不能比 novel 活得久。
为啥要这么搞?因为 struct 一旦有了引用字段,它就不再是独立的"自包含"对象,它依赖外部的数据存活。Rust 必须知道这种依赖关系,才能保证安全。
实际上,初学的时候大部分情况下你都不应该让 struct 持有引用,让 struct 拥有 String 而不是 &str、拥有 Vec<T> 而不是 &[T],写起来简单很多。只有性能敏感、确实需要避免拷贝的时候,才考虑用引用 + 生命周期。
生命周期省略规则
看到这里读者可能会嘀咕:那为啥前面那么多代码都没写生命周期,也都能编译?比如:
fn first_word(s: &str) -> &str {
// ...
s
}这个返回了一个引用,按道理需要标注啊。
答案是:Rust 有一套生命周期省略规则(lifetime elision rules),有些常见的情况编译器自己能推出来,就不需要你写了。规则一共三条:
- 每个引用参数都有自己的生命周期参数。比如
fn f(x: &i32, y: &i32)实际等价于fn f<'a, 'b>(x: &'a i32, y: &'b i32) - 如果只有一个输入生命周期,那它就赋给所有输出生命周期
- 如果有多个输入生命周期,但其中有
&self或&mut self,那 self 的生命周期赋给所有输出生命周期
第二条覆盖了大部分常见情况。比如 fn first_word(s: &str) -> &str,输入只有一个引用,输出的生命周期就跟输入一样,编译器自己推出来。
第三条是为实例方法服务的。Rust 觉得"方法返回的引用,大概率是借自 self",所以默认就这么推。
如果不符合这三条规则(比如前面 longest 那种"两个引用参数都不是 self、编译器没法决定返回值借自哪个"的情况),编译器就会报错让你手动标。
实际写代码的时候,刚开始报这种错很正常,看错误提示加上对应的 <'a> 就行。写多了就有感觉了。
'static 生命周期
有一个特殊的生命周期叫 'static,表示"活到程序结束"。前面字符串那节我们提过,字符串字面量的类型就是 &'static str,因为它们写死在二进制里,整个程序运行期间都存在:
let s: &'static str = "I have a static lifetime.";'static 听起来很美好,活得最久,谁都能用。但要小心,不要看到编译器提示 &'static 就无脑加上去,那通常是把问题藏起来了,不是真的解决问题。'static 应该用在那些你确信"这玩意儿真的会一直活到程序结束"的地方,比如全局常量、配置数据、Box::leak 出来的内存。
另外,'static 还有第二个含义,是作为 trait bound 用的:T: 'static 表示"T 不包含任何生命周期短于 'static 的引用"。这个含义在多线程那块会反复出现(因为线程可能存活到程序结束),先不展开,知道有这么个东西就行。
啥时候真的需要关心生命周期?
讲了这么多,最后给个实用的判断:
- 写普通业务代码、struct 不持有引用 → 几乎用不到生命周期标注
- 写函数返回引用、且参数有多个引用 → 可能要标
- 写 struct 持有引用 → 必须要标
- 写库代码、追求零拷贝 → 频繁要标
- 写异步代码 → 经常被生命周期问题坑(async 那块情况复杂,后面讲)
新手项目里,遇到生命周期问题最简单的解决方式往往是"换成拥有的类型",比如&str 改成 String,&[T] 改成 Vec<T>。性能可能差一点点,但代码简单很多。等你对所有权和借用有了肌肉记忆,再去考虑零拷贝优化也来得及。
Rust 的生命周期是它独有的设计,刚开始确实费脑子。但好消息是:编译器报错信息一般都很清晰,能告诉你哪两个生命周期对不上,按提示改基本能改对。习惯就好。
到这里 Rust 类型系统的核心三件套:泛型、trait、生命周期,现在就都讲完了。其实也没那么复杂,对于 Java 开发者来说,泛型非常简单,几乎和 Java 差不多,trait 和接口其实也差不了多少,只不过功能强大一些,lifetime 算是一个新东西,但是用的地方其实不多。
十三、闭包和迭代器:跟 Java Stream 思路一致,但更深入
Java 程序员对这两个东西其实不陌生:Java 8 引入的 lambda 和 Stream API 思路上跟它们高度一致。所以这一节的学习曲线不陡,主要是了解 Rust 在所有权约束下的一些细节差异。
闭包:跟 Java lambda 几乎一样
闭包语法:
let add = |a: i32, b: i32| -> i32 { a + b };
let result = add(1, 2); // 3写法是 |参数| 表达式 或者 |参数| { 多行 }。跟 Java 的 (a, b) -> a + b 思路一样,只不过参数列表用 || 包起来。
类型一般可以省略:
let add = |a, b| a + b;
let r = add(1_i32, 2); // OK,编译器从第一次调用推出 a, b 是 i32但要注意,闭包的参数和返回类型一旦推出来就固定了,不能像泛型函数那样多次用不同类型调用:
let add = |a, b| a + b;
let r1 = add(1_i32, 2);
let r2 = add(1.0_f64, 2.0); // 编译错误!add 的参数类型已经定为 i32 了可能大家看到这里会觉得有点奇怪,但是如果你了解了闭包在经过编译器转换以后其实就是一个结构体,可能就知道为什么了。
闭包最大的特点是捕获环境。Java 的 lambda 也能捕获外部变量,但只能捕获 final 或 effectively final 的:
int x = 10;
Runnable r = () -> System.out.println(x); // OK,x 是 effectively final
// x = 11; // 这样就不行,因为 r 里捕获了 xRust 的闭包能捕获各种形式,分得比 Java 更细。
三种 Fn trait:闭包的三种"档位"
Rust 没有 Java 那种"functional interface"的概念,闭包是怎么搞的?答案是 trait。Rust 标准库里有三个 trait 用来表示闭包,按"对环境的占用程度"分三档:
FnOnce:只能调用一次(会消费掉捕获的值)FnMut:可以多次调用,并且会修改捕获的值Fn:可以多次调用,只读捕获
这三个是层层包含的关系:能 Fn 的肯定能 FnMut 和 FnOnce,能 FnMut 的肯定能 FnOnce。
什么样的闭包属于哪一档?编译器会根据闭包对捕获变量做了什么自动推:
// 只读捕获 → Fn
let s = String::from("hello");
let print_s = || println!("{s}");
print_s();
print_s(); // 多次调用没问题
// 修改捕获 → FnMut
let mut s = String::from("hello");
let mut append = || s.push_str(" world");
append();
println!("{s}"); // "hello world"
// 移动并消费捕获 → FnOnce
let s = String::from("hello");
let consume = move || { let _moved = s; }; // s 被移到 _moved 里,闭包用一次就废了
consume();
// consume(); // 编译错误:FnOnce 只能调用一次这三档对应的就是前面所有权那节讲的三种引用方式:&self、&mut self、self。是不是又串起来了?Rust 的概念有种很爽的"环环相扣"感。
move 关键字:强制拿走所有权
默认情况下闭包用最弱的捕获方式:能用 & 就用 &,需要改才用 &mut,需要消费才 move。但有时候我们想强制让闭包拿走所有权,特别是把闭包传到另一个线程里:
use std::thread;
let s = String::from("hello");
let handle = thread::spawn(move || { // move 强制把 s 移进闭包里
println!("from thread: {s}");
});
handle.join().unwrap();为啥要 move?因为子线程可能比 s 所在的作用域活得更久,如果还是借用方式,s 一被释放子线程就拿到悬垂引用了。move 让闭包把 s 整个拿走,所有权转移到子线程那边,安全。
这个东西后面讲并发的时候还会反复见,先有印象就行。
迭代器:跟 Java Stream 思路一样
接下来是迭代器。Java 程序员对 Stream API 已经很熟了:
int sum = list.stream()
.filter(x -> x > 2)
.mapToInt(x -> x * 2)
.sum();Rust 写起来差不多:
let sum: i32 = v.iter()
.filter(|&&x| x > 2)
.map(|x| x * 2)
.sum();迭代器的核心是 Iterator trait,简化版长这样:
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// 还有一大堆默认方法:map, filter, fold, sum, collect 等等
}只要给一个类型实现 next 方法,剩下的几十个组合都白送,这是 trait 默认方法的威力。
iter / iter_mut / into_iter:三种迭代方式
集合那节我们提过这三个方法,这里展开说一下。它们的区别就一句话:拿什么形式的引用:
let v = vec![1, 2, 3];
v.iter(); // 产生 &T,只读借用
v.iter_mut(); // 产生 &mut T,可变借用,可以修改元素
v.into_iter(); // 产生 T,拿走所有权,迭代完原集合就没了for x in v 这个语法糖等价于 v.into_iter(),所以默认会拿走所有权。这就是为什么集合那节我们写:
for x in &v { // 显式借用,等价于 v.iter()
println!("{x}");
}
for x in &mut v { // 等价于 v.iter_mut()
*x += 10;
}
for x in v { // 等价于 v.into_iter(),迭代完 v 就用不了
println!("{x}");
}接下来,我们来解释这行代码:
let sum: i32 = v.iter().filter(|&&x| x > 2).map(|x| x * 2).sum();v.iter() 产生的是 &i32(不是 i32),这很好理解,这个方法返回的是只读借用,filter 接收的闭包参数类型是 &Item,所以 filter 那个闭包拿到的是 &&i32:
v.iter() // 迭代器产生 &i32
.filter(|x| /* x: &&i32 */ ) // filter 拿到的是 &Item
.map(|x| /* x: &i32 */ ) // map 拿到的是 Item
.sum()那 |&&x| 是啥?是模式匹配解构:
- 第一个
&解掉外层的&&i32→&i32 - 第二个
&解掉内层的&i32→i32
最后 x 就是 i32,可以直接 x > 2 比较,写起来更顺。
如果你觉得 |&&x| 反人类,写成下面这样也对:
v.iter().filter(|x| **x > 2) // 不解构,调用时手动解引用
v.iter().filter(|&&x| x > 2) // 解构,写法上看起来怪一点
v.iter().copied().filter(|&x| x > 2) // 先 copy 一层,让迭代器产生 i32 而不是 &i32一般大家都是怎么顺怎么来,一时不理解也没关系,记住就行了。Rust 编译器对引用和解引用的容忍度很高,多种写法都能编过。
惰性求值
跟 Java Stream 一样,Rust 的迭代器也是惰性的:你写一串 .map(...).filter(...) 啥都不会发生,只有调用了消费方法才会真的执行:
let v = vec![1, 2, 3];
let it = v.iter().map(|x| {
println!("processing {x}");
x * 2
});
// 到这里啥都不打印
for x in it {
println!("got {x}");
}
// 这时候才开始打印 processing 1, got 2, processing 2, got 4...注意 Rust 是真正的"逐个产生",上面这段代码,map 不会一次性把整个 vec 处理完再给下面的 for代码块,而是 for 每问一个,map 才算一个。这跟 Java Stream 也一样。
常见的消费方法:
.collect() // 收集到一个集合里,类似 Java 的 .collect(Collectors.toList())
.sum() // 求和
.count() // 计数
.fold(...) // 类似 Java 的 reduce
.for_each(...)// 副作用迭代
.find(...) // 找第一个满足条件的,返回 Option
.any(...) // 是否有满足条件的,返回 bool
.all(...) // 是否所有都满足collect 这个特别提一下,它需要你告诉它收到什么类型里:
use std::collections::HashSet;
let v: Vec<i32> = (1..=10).filter(|x| *x % 2 == 0).collect(); // 收到 Vec
let s: HashSet<i32> = (1..=10).filter(|x| *x % 2 == 0).collect(); // 收到 HashSet
let s: String = ['h', 'i'].into_iter().collect(); // 收到 String类型由声明决定,编译器根据目标类型反推 collect 该怎么收。这是 Rust 类型推导的一个强大用法。如果不想写在变量上,也可以这样传:.collect::<Vec<_>>(),效果一样。
零成本抽象
说到迭代器,一定要提一句 Rust 的"零成本抽象"。Java Stream 用起来爽,但要付出一些代价:装箱拆箱、虚函数调用、临时对象分配等等。Rust 的迭代器经过单态化和内联优化,编译出来的代码跟手写循环几乎一模一样:
// 这个高级写法
let sum: i32 = (1..=100).filter(|x| *x % 2 == 0).sum();
// 编译之后的效率,约等于这个手写版本
let mut sum = 0_i32;
for i in 1..=100 {
if i % 2 == 0 {
sum += i;
}
}所以在 Rust 里你可以放心大胆用迭代器链式调用,不用担心性能。Java 那边对性能敏感的代码,有时候还是会回退到 for 循环,Rust 这边没这个顾虑。
自定义迭代器
最后看一眼怎么自己实现一个迭代器。其实就是给类型实现 Iterator trait,提供 next 方法:
struct Counter {
count: u32,
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<u32> {
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None // 返回 None 就表示迭代结束
}
}
}
let c = Counter { count: 0 };
for x in c {
println!("{x}"); // 1, 2, 3, 4, 5
}
// 实现了 Iterator 之后,map/filter/sum 这些方法全都自动可用
let total: u32 = Counter { count: 0 }.sum();跟 Java 的 Iterator 接口接近,只不过 Java 的接口里 hasNext 和 next 是分开的,Rust 把"还有没有"和"取下一个"打包到 Option 里返回,更紧凑。这种"用 Option 表达可能没有"的设计在 Rust 里到处都是,前面 HashMap 的 get 也是这个套路。
到这里闭包和迭代器就讲完了。这一节因为有 Java Stream 打底,应该是比较好理解的一节。
十四、智能指针:Rust 里的"特殊引用"
前面我们一直在用普通的引用 &T 和 &mut T,这些在所有权和借用规则里都很自然。但有些场景普通引用满足不了,比如:
- 数据要放堆上(普通引用不能控制分配位置)
- 同一份数据需要多个所有者(违反"单一所有者"规则)
- 在
&self方法里也想修改某个字段(违反借用规则)
这些场景就要用到智能指针(smart pointer)。Rust 里的智能指针其实就是一些特殊的类型,行为上像指针,但带了额外能力。我们这一节讲最常用的几个:Box、Rc、RefCell、Arc、Mutex、Weak。
讲之前先说一句:智能指针这个名字听起来很高大上,其实没那么玄乎。Rust 的"智能指针"基本上都是普通的 struct,里面包了一个指针 + 一些控制逻辑。String 严格说也算一种智能指针(它管理一段堆上的 UTF-8 数据)。所以不要被名字吓到。
Box<T>:最基础的堆分配
Box<T> 是最简单的智能指针,作用就是把 T 放到堆上:
let b = Box::new(5); // 在堆上分配一个 i32,值为 5
println!("b = {b}"); // 5,自动解引用类比 Java:Java 里所有对象都在堆上,引用在栈上指过去,这是默认行为。Rust 里基础类型默认在栈上,要放堆上就得 Box::new(...)。所以可以理解成 Box::new(x) 就是 Java 里"new 这个值放堆上"的显式写法,理解了这个,Box 就非常简单了。
Box<T> 拥有所有权,离开作用域时会自动释放堆上的内存(GC 的工作 Rust 在编译期就安排好了):
{
let b = Box::new(5);
// 用 b
} // 这里 b 离开作用域,堆内存自动释放Box 在三种场景里特别有用。
第一种,递归类型。这也是官方教程使用的例子,我们如果要写一个链表:
enum List {
Cons(i32, List), // 编译错误:infinite size
Nil,
}这编译不过,因为编译器要算 List 的大小,发现里面又包了一个 List,无限递归没法算。用 Box 就行:
enum List {
Cons(i32, Box<List>), // Box 的大小是固定的(一个指针的大小)
Nil,
}Box<List> 是一个指针,大小固定,编译器能算出来。这跟 Java 不一样:Java 里链表节点之间天然就是引用关系,根本不会遇到这个问题。Rust 因为默认是嵌入式存储(值直接放进去),所以才需要 Box 来"打断"递归。
第二种,很大的对象,避免 move 时拷贝整个数据。
第三种,Box<dyn Trait> 做动态分发,前面 trait 那节我们介绍过这么一行代码:
let greeters: Vec<&dyn Greet> = vec![&english, &chinese];但其实一般我们会这么用:
let greeters: Vec<Box<dyn Greet>> = vec![
Box::new(English),
Box::new(Chinese),
];Deref 和 Drop:智能指针之所以"智能"
这里顺便提两个 trait,所有智能指针都会实现。
Deref 是解引用,让智能指针可以像普通引用一样用:
let b = Box::new(5);
let n = *b; // 解引用,拿到 5。这背后调用的是 Box 的 Deref 实现更常见的是"自动解引用",你调用方法时编译器会自动帮你解:
let s = Box::new(String::from("hello"));
println!("{}", s.len()); // 编译器自动解引用,相当于 (*s).len()Drop 相当于 Java 的 finalizer,但比 finalizer 靠谱得多,它的执行时机是确定的(变量离开作用域时立即执行),而 Java 的 finalize 啥时候被调用全看 GC 心情:
struct Logger;
impl Drop for Logger {
fn drop(&mut self) {
println!("Logger dropped!");
}
}
{
let _l = Logger;
} // 这里打印 "Logger dropped!"Rust 的 Drop 跟 C++ 的析构函数差不多,是 RAII(资源获取即初始化)模式的体现。Java 后来引入的 try-with-resources 也是 RAII 思想,但只在 try 块里有效,没法在变量离开作用域时自动触发。
知道有这俩 trait 就行,平时一般不用自己实现。
Rc<T>:单线程下的多所有权
Rust 的所有权规则说"一个值只能有一个 owner"。这在大部分场景下没问题,但有些场景就憋屈了,比如图、树、共享数据结构等等,这种数据天然就是多个地方在引用同一份数据。
Rc<T>(reference counted)就是用来处理这种情况的。它在内部维护一个引用计数,每次 clone 就 +1,每次 drop 就 -1,计数为 0 时才真正释放数据:
use std::rc::Rc;
let a = Rc::new(String::from("hello"));
println!("count: {}", Rc::strong_count(&a)); // 1
let b = Rc::clone(&a);
println!("count: {}", Rc::strong_count(&a)); // 2
{
let c = Rc::clone(&a);
println!("count: {}", Rc::strong_count(&a)); // 3
} // c 离开作用域,count 减回 2注意 Rc::clone(&a) 跟你想象的"clone 一份数据"不一样,它只是把引用计数 +1,底层数据还是同一份。这点跟 Java 里"复制引用"(多个变量指向同一个对象)思路是一样的。
Rc::clone 也可以写成 a.clone(),效果相同。社区习惯写 Rc::clone(&a) 是为了让"这是引用计数 +1,不是深拷贝"这件事一眼能看出来。
Rc<T> 有两个限制必须强调:
- 只能用在单线程。多线程要用
Arc<T>(稍后讲)。 - 拿到的内容是不可变的。
Rc<T>只给你&T,不会给&mut T,因为多个 Rc 指向同一份数据,给可变引用就违反借用规则了。
第二点很要命:很多场景我们就是想要"多个所有者,且能修改"。怎么办?这就要看下面这位了。
RefCell<T>:把借用检查推到运行时
RefCell<T> 提供的能力叫内部可变性(interior mutability):你拿着 &T(不可变引用),但可以"通过它"修改里面的数据。
听起来违反借用规则?是的,但 RefCell 在运行时自己检查规则:
use std::cell::RefCell;
let c = RefCell::new(5);
{
let r = c.borrow(); // 不可变借用
println!("{}", *r);
} // r 离开作用域,借用结束
{
let mut r = c.borrow_mut(); // 可变借用
*r += 1;
}
println!("{}", c.borrow()); // 6borrow() / borrow_mut() 这俩方法在运行时跟踪借用情况,规则跟编译期借用检查一样:要么有任意多个 borrow(),要么只有一个 borrow_mut()。违反的话直接 panic:
let c = RefCell::new(5);
let r1 = c.borrow_mut();
let r2 = c.borrow(); // 运行时 panic!already borrowed mutably可能有读者要问:好端端的编译期检查为啥要换成运行时检查?答案是:编译器看不到所有信息。比如下面这种:
struct MyType {
cache: RefCell<HashMap<String, String>>, // cache 是内部状态
}
impl MyType {
fn get(&self, key: &str) -> String { // 注意是 &self,不是 &mut self
let mut cache = self.cache.borrow_mut();
// 在 &self 方法里修改 cache,靠 RefCell 实现
// ...
String::new()
}
}这个一个本地缓存的设计,从外部看,MyType::get 是一个不可变方法(参数是 &self)获取缓存中的值,但内部需要更新 cache。这种"对外不可变,对内有副作用"的场景,编译器没法在 &self 上让你拿 &mut HashMap,只能用 RefCell 把检查推到运行时。
RefCell<T> 也有限制:只能单线程用。多线程要用 Mutex<T> 或 RwLock<T>。
Rc<RefCell<T>>:经典组合
把 Rc 和 RefCell 套起来,就得到了"多所有者 + 可变"的组合,这是 Rust 里非常常见的模式:
use std::rc::Rc;
use std::cell::RefCell;
let shared = Rc::new(RefCell::new(vec![1, 2, 3]));
let a = Rc::clone(&shared);
let b = Rc::clone(&shared);
a.borrow_mut().push(4);
b.borrow_mut().push(5);
println!("{:?}", shared.borrow()); // [1, 2, 3, 4, 5]Rc<RefCell<T>> 在功能上接近 Java 里的"普通对象引用",多个变量指向同一份数据,谁都能改。代价是:每次访问都要走一次 borrow() / borrow_mut(),运行时有少量开销,违反规则会 panic。
写图、树这种共享数据结构时,Rc<RefCell<T>> 几乎是逃不掉的。
Arc<T> 和 Mutex<T>:多线程版本
Rc 和 RefCell 都只能在单线程用,因为它们内部的计数和借用跟踪都不是原子的。多线程版本是:
Arc<T>(atomic reference counted):多线程版本的RcMutex<T>/RwLock<T>:多线程版本的RefCell
Arc 跟 Rc 用法几乎一样,只是 clone 时的计数操作是原子的:
use std::sync::Arc;
use std::thread;
let data = Arc::new(vec![1, 2, 3]);
let mut handles = vec![];
for i in 0..3 {
let data = Arc::clone(&data);
handles.push(thread::spawn(move || {
println!("thread {i} sees: {:?}", data);
}));
}
for h in handles {
h.join().unwrap();
}Mutex<T> 就是 Java 的 synchronized + 一个对象的组合体,它把"锁"和"被保护的数据"绑在一起:
use std::sync::Mutex;
let m = Mutex::new(0); // m 不仅是一个锁,也是一个数据的载体
{
let mut num = m.lock().unwrap(); // 拿锁
*num += 1;
} // num 离开作用域,锁自动释放注意这里跟 Java 的本质差别:Java 的 synchronized 锁的是任意对象,编译器并不知道你具体要保护什么数据,靠程序员自觉;Rust 的 Mutex<T> 把数据装在锁里面,没拿到锁就根本访问不到数据。这是非常 Rust 的设计:把"必须先加锁"这件事直接做进类型系统里,让你不可能写错。
Arc<Mutex<T>> 是多线程下"多所有者 + 可变"的标准组合,对应单线程的 Rc<RefCell<T>>。并发这块后面有专门一节,到时候再展开。
新手刚开始写 Rust,最容易卡在所有权和借用上,往往会被建议"上 Rc<RefCell<T>> 解决一切"。这个建议对入门有用:能跑就比啥都强。但写多之后会发现,真正写得"地道"的 Rust 代码,会尽量避免这些智能指针,靠合理的所有权设计就能搞定。智能指针是工具,但用得多了说明设计上有冗余,能少用就少用。
十五、模块系统:怎么把代码组织起来
写到这里我们的代码都是单文件的小例子,真实项目肯定不能这么写。这一节我们看 Rust 怎么把代码组织成多个文件、怎么暴露 API、怎么管理可见性。
跟 Java 比,Rust 的模块系统有相似的地方,也有挺独特的地方。我们一边讲一边对比。
怎么对应 Java 多 module 项目
我们直接从一个真实场景切入。Java 项目里我们经常用 Maven/Gradle 把代码拆成多个 module,比如一个典型的 web 项目:
myapp/
├── pom.xml
├── myapp-api/ # 接口定义、DTO
├── myapp-data/ # 数据层,entity、repository
├── myapp-common/ # 公用工具
└── myapp-web/ # controller、REST endpoint,启动应用的入口Rust 怎么对应?两个核心概念先记住:
- crate:Rust 的"编译单元",一份独立编译出来的产物(库或可执行文件),对应 Java 的一个 Maven module / 一个 jar 包
- module(
mod关键字):crate 内部的命名空间,对应 Java 的 package
这里要特别注意一下,Rust 的 module 跟 Java 的 module 名字一样但完全不是一回事。Java 的 module 对应 Rust 的 crate,而 Rust 的 module 对应 Java 的 package。
至于"多个 module 一起组成一个项目"这种形式,Rust 里叫 workspace。前面那个 Java 项目,Rust 写出来大概长这样:
myapp/
├── Cargo.toml # workspace 配置
└── crates/
├── api/ # 类似 myapp-api
│ ├── Cargo.toml
│ └── src/lib.rs
├── data/ # 类似 myapp-data
├── common/ # 类似 myapp-common
└── web/ # 类似 myapp-web,binary crate(src/main.rs),启动入口每个子目录都是一个独立的 crate,有自己的 Cargo.toml。根目录的 Cargo.toml 用来声明 workspace:
# 根 Cargo.toml
[workspace]
resolver = "2"
members = ["crates/*"]crate 之间通过路径依赖串起来:
# crates/web/Cargo.toml
[dependencies]
api = { path = "../api" }
data = { path = "../data" }
common = { path = "../common" }跟 Maven 的 <modules> + <dependency> 思路完全对得上。整个 workspace 共享一个 Cargo.lock 和 target/ 目录,编译出来的依赖可以复用,不会每个 crate 重复编译同一个东西。
也有把 crate 直接平铺在根目录、不另开 crates/ 子目录的,两种风格都常见,看个人喜好。tokio、bevy 这种大型开源项目基本都是 workspace 组织。
至于 Cargo 文档里偶尔出现的"package",一个 Cargo.toml 管的项目就是一个 package,里面默认包含一个 lib crate(src/lib.rs)加任意个 binary crate(src/main.rs 或 src/bin/*.rs)。简单项目里 package 跟 crate 基本是 1:1 的,平时不用刻意区分。
写个命令行小工具,cargo new myapp 单 crate 就够;要做多模块项目,再上 workspace。
mod:定义模块
模块用 mod 关键字声明,最简单的形式是把模块写在同一个文件里:
mod network {
pub fn connect() {
println!("connecting...");
}
pub mod server { // 模块可以嵌套
pub fn run() {
println!("server running");
}
}
}
fn main() {
network::connect();
network::server::run();
}模块路径用 :: 隔开,不像 Java 用 .。这跟 C++ 的命名空间风格一致。
文件组织:从单文件到多文件
把所有模块塞一个文件显然不现实。Rust 的文件组织规则其实很简单,但讲之前先强调一个跟 Java 非常不一样的地方,初学 Rust 几乎人人都会踩这个坑:
Rust 不会按文件系统自动把代码包含进项目,文件得在父模块里
mod xxx;显式声明,编译器才认。
Java 是按目录扫描的,.java 文件放对位置编译器就自动收。Rust 不是这样:你新建了 src/foo.rs,写了一堆代码,但只要没人在 lib.rs 或父模块里写 mod foo;,编译器就当这个文件不存在,cargo build 还照过。典型症状是新加的函数用起来报"找不到",十有八九就是忘了在父模块里 mod 声明。
知道这点,我们再看具体规则。
假设我们写一个库 crate,入口是 src/lib.rs:
// src/lib.rs
mod network; // 注意这里没有大括号,告诉编译器去找文件
mod utils;这一行 mod network; 告诉编译器:去找一个叫 network 的模块,文件可能在:
src/network.rs(推荐,新写法)src/network/mod.rs(老写法,仍然支持)
任选其一即可,但一个项目里一般统一用一种风格。
如果 network 模块本身又有子模块,按同样的规则继续。新写法下文件结构长这样:
src/
├── lib.rs # mod network; mod utils;
├── network.rs # 里面写: mod server; mod client;
├── network/
│ ├── server.rs # network::server 的实现
│ └── client.rs # network::client 的实现
└── utils.rs注意 network.rs 和 network/ 目录是配套的,network.rs 是模块本身,network/ 目录里放它的子模块。这种"文件 + 同名目录"的组织看起来有点别扭,但用熟了就好。
老写法是用 mod.rs:
src/
├── lib.rs
├── network/
│ ├── mod.rs # 这个文件就是 network 模块
│ ├── server.rs
│ └── client.rs
└── utils.rs老项目里 mod.rs 还很常见,新项目大家更喜欢前一种风格。原因之一是:一堆 mod.rs 在 IDE 里打开后标签页全是 "mod.rs",分不清楚。
路径:怎么引用东西
模块里的东西怎么引用?Rust 有几种路径写法:
// 绝对路径,从 crate 根开始
crate::network::server::run();
// 相对路径,从当前模块开始
network::server::run();
// self 表示当前模块
self::server::run();
// super 表示父模块,类似目录里的 ..
super::utils::helper();crate、self、super 这三个关键字在路径里很常用,记住就行。
pub:控制可见性
模块和模块里的东西默认都是私有的,这点跟 Java 不一样。Java 默认是 package-private,至少包内可见;Rust 默认连父模块都看不见。
要对外暴露,得加 pub:
mod network {
fn private_helper() {} // 只在 network 模块内可见
pub fn connect() { // 父模块可见
private_helper();
}
}pub 还有几个变体,控制粒度更细:
pub // 完全公开
pub(crate) // 仅当前 crate 内可见,对 crate 外(比如别人用你的库时)不可见
pub(super) // 仅父模块可见
pub(in path) // 在指定路径内可见pub(crate) 用得最多,意思是"我自己这个项目里随便用,但别人通过依赖引入这个 crate 的时候看不到"。
struct 的字段也是默认私有的,需要单独标 pub:
pub struct User {
pub name: String, // 字段公开
age: u32, // 字段私有
}把 struct 标成 pub 不会让它的字段也跟着 pub,得逐个标。这点其实跟 Java 一致,public class 里的字段默认也不是 public,要单独写。
use:把路径引入作用域
模块路径经常很长,每次写全名很烦。use 解决这个问题:
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert("a", 1);
}这个跟 Java 的 import 思路一样。也支持几个进阶用法:
// 重命名(Java 里不能给 import 起别名,得用全名)
use std::io::Result as IoResult;
// 同模块下多个东西
use std::collections::{HashMap, HashSet, BTreeMap};
// 引入模块本身和它的内容
use std::io::{self, Read}; // 引入 io 模块和 io::Read
// glob 引入(不推荐用在普通代码里,名字会污染)
use std::collections::*;最后一个 use std::collections::*; 跟 Java 的 import x.y.*; 类似,但 Rust 社区里基本只在测试模块和 prelude 里用,普通代码里都老老实实把要用的东西列清楚。
prelude:为什么很多东西不用 use
写到这里你应该会有个疑问:前面我们用 Option、Result、String、Vec 这些都没写过 use,为啥?
因为 Rust 有一个 prelude(预导入),里面放了一批最常用的类型和 trait,所有模块都自动 use 进来。这就是为啥 Option、Vec 你直接用就行。
你可以理解成 Java 里 java.lang.* 自动导入的机制,思路完全一样。不过 Rust 的 prelude 比 java.lang 范围大一些,里面除了类型还包含了一批 trait,比如 Clone、Iterator、Drop 等。
pub use:重导出
pub use 是一个挺有用的进阶用法,意思是"把别的地方的东西重新暴露在我这里":
// src/lib.rs
mod inner;
pub use inner::SomeType; // 把 inner::SomeType 在 crate 根重新暴露这样下游使用方就可以写 mycrate::SomeType 而不是 mycrate::inner::SomeType,对外提供更扁平的 API,同时保留内部的层级结构。一个常见的应用就是在 lib.rs 里集中重导出,给用户一个干净的 API 表面。
workspace 的几个实用配置
回到一开始我们那个多 crate 项目。真实工程里,每个 crate 都重复写一遍 edition = "2021"、serde = "1" 这种依赖会很烦。Cargo 提供了几个 workspace 级别的配置帮你减少重复,写大项目几乎一定会用到。
第一个常用的是 共享依赖版本:
# 根 Cargo.toml
[workspace]
resolver = "2"
members = ["crates/*"]
[workspace.dependencies]
serde = { version = "1", features = ["derive"] }
tokio = { version = "1", features = ["full"] }
anyhow = "1"成员 crate 引用:
# crates/web/Cargo.toml
[dependencies]
serde.workspace = true # 直接用 workspace 里定义的版本
tokio.workspace = true
api = { path = "../api" }这样升级一次依赖版本,所有用到它的 crate 一起跟着升,不会出现"web 用 serde 1.0.150 而 data 用 1.0.180"的版本错位。Maven 的 <dependencyManagement> 思路类似,但 Cargo 这套写法明显比 pom.xml 干净。
第二个是 共享 package 元数据,比如 edition、version、license 这些:
[workspace.package]
edition = "2021"
version = "0.1.0"
license = "MIT"
authors = ["Your Name"]成员里继承:
# crates/web/Cargo.toml
[package]
name = "web"
edition.workspace = true
version.workspace = true
license.workspace = true第三个我个人觉得很重要的是 统一的 lint 配置。Rust 项目里大家通常会要求开很多 clippy 警告,可以集中管理:
# 根 Cargo.toml
[workspace.lints.clippy]
unwrap_used = "warn"
expect_used = "warn"成员里:
# crates/web/Cargo.toml
[lints]
workspace = true这样所有 crate 共享同一套规则,新加的 crate 也跟着一起被约束。
这几个配置加起来,整个 workspace 的依赖版本、编辑版本、lint 规则都统一了,新加一个 crate 时 Cargo.toml 可以写得非常薄,跟 Maven 父 pom 里集中管理 <properties> 的体验差不多,但写法更紧凑。
跟 Java 的几个差异点
讲到这里,模块系统的核心内容差不多了,最后回头梳理一下跟 Java 的几个关键差异:
- Java 默认 package-private,Rust 默认完全私有,需要主动
pub - Java 的包 = 目录结构,强制对应;Rust 用
mod声明,多一层灵活性 - Java 的 import 没法起别名,Rust 的
use可以as - Java 没有 workspace 内置概念(Maven 多 module 是 Maven 的功能,不是 Java 的);Rust 把 workspace 做进 Cargo 里
- Rust 的 prelude 让常用类型直接可用,跟 Java 的
java.lang类似但范围更大
模块系统这块没啥难的,就是要熟悉一下规则。
十六、宏:Rust 的元编程
写到这里我们用过不少宏了:println!、vec!、format!、#[derive(Debug)] 等等。一直没专门讲宏是什么、它跟普通函数有啥区别。这一节我们把这个坑填上。
Java 程序员对"宏"这个词可能比较陌生,因为 Java 里没有真正意义上的宏系统,最接近的可能是注解处理器(annotation processor)和编译期的 Lombok,但能力跟 Rust 的宏比起来差挺多。我们一边讲一边对比。
说实话,宏代码真的很难写,这节主要是介绍一些基本的概念,以确保本文的完整性,实际工作中,肯定是把需求描述清楚,让 AI 来帮我们写的。别说写宏的代码了,就是看别人的实现都费劲,我们接触到一个宏,大概知道它是做了哪些事情,怎么用,我觉得就行了。
为啥要有宏?有哪几类宏?
最简单的疑问:函数能解决的事情为啥要搞宏?
答案是:函数解决不了某些事情。比如 println!:
println!("name: {name}, age: {age}");这一行做的事是:在编译期检查字符串里的 {name} 和 {age} 是不是真的存在对应的变量、类型对不对。Java 的 String.format 是运行时才解析格式串,传错了运行时才报错;Rust 的 println! 编译期就把这事检查了。
再比如 vec![1, 2, 3],它接受可变数量的参数。Rust 的普通函数没法接受可变参数(不像 Java 的 varargs),但宏可以。
总结一下,宏能做但函数做不了的事:
- 接受可变数量、可变形式的参数
- 在编译期生成代码(包括根据某些信息派生 trait 实现)
- 检查/解析字符串字面量、类型等编译期信息
Rust 里宏调用有下面几种形式:
println!(...) // 函数式宏,带 ! 后缀
vec![...] // 函数式宏,可以用 () 或 [] 或 {}
#[derive(Debug)] // 派生宏,加在类型上
#[tokio::main] // 属性宏,加在函数/类型上Rust 的宏分两大类:
- 声明宏(declarative macros):用
macro_rules!定义,通过模式匹配把宏调用展开成代码 - 过程宏(procedural macros):用 Rust 代码处理一棵语法树,再生成新的语法树
声明宏简单、易写,能力有限;过程宏更强大,但要单独搞一个 proc-macro crate,写起来麻烦。
声明宏:macro_rules!
声明宏其实就是一个正则替换游戏。
看一个简单例子:
macro_rules! say_hi {
() => {
println!("Hi!");
};
}
fn main() {
say_hi!();
}这个宏没参数,就是把 say_hi!() 展开成 println!("Hi!");。语法是 (模式) => { 展开 },可以有多个分支用 ; 隔开。
带参数的版本:
macro_rules! greet {
($name:expr) => {
println!("Hello, {}!", $name);
};
}
greet!("javadoop"); // 展开成 println!("Hello, {}!", "javadoop");$name:expr 表示捕获一个表达式,命名为 name。expr 是片段类型(fragment specifier),还有 ident(标识符)、ty(类型)、pat(模式)、stmt(语句)等。
支持重复匹配,类似正则的 * 和 +:
macro_rules! my_vec {
( $( $x:expr ),* ) => {
{
let mut v = Vec::new();
$(
v.push($x);
)*
v
}
};
}
let v = my_vec![1, 2, 3];$( $x:expr ),* 表示匹配零个或多个表达式、用逗号隔开。展开时用同样的 $( ... )* 包起来,里面引用 $x 就会按匹配的次数重复展开。
这个 my_vec! 其实就是标准库 vec! 宏的简化版。
声明宏的能力其实挺有限,主要就是模式匹配 + 重复,非常好理解。它适合写一些简单的语法糖、消除重复代码,但写不了太复杂的逻辑。
过程宏:三种形式
过程宏的能力强得多。它本质上是一段 Rust 代码,输入是 Token 流,输出也是 Token 流,中间你想干啥都行,通常会配合 syn 这个库去解析语法树,配合 quote 这个库去生成代码。
过程宏分三种形式。
派生宏(derive macros):加在 struct/enum 上,自动生成 trait 实现。这个我们前面用过最多:
#[derive(Debug, Clone, PartialEq)]
struct User {
name: String,
age: u32,
}#[derive(Debug)] 就是一个派生宏,它会展开成一个 impl Debug for User 的实现。整个标准库里 Debug、Clone、Default、PartialEq、Eq、Hash 这些都能 derive。第三方库也大量使用派生宏,比如 serde 的 #[derive(Serialize, Deserialize)]、thiserror 的 #[derive(Error)]。总之,它就是为了让 struct 实现某些 trait 来设计使用的。
属性宏(attribute macros):可以加在几乎任何东西上,对它做转换:
#[tokio::main]
async fn main() { // 看上去好像这个方法不符合 Rust 的 main 入口规范,但是编译器在编译期会做展开的
// ...
}
#[get("/hello")]
fn hello() -> String {
String::from("hi")
}#[tokio::main] 最终会把一个 async fn main 包装成一个普通的 fn main,里面建一个 tokio 运行时来跑,所以不要以为 Rust 支持其他形式的 main 函数,不过都是宏带给我们的假象。#[get("/hello")]` 是 web 框架(比如 actix-web、rocket)用来注册路由的。
函数式宏(function-like macros):调用形式跟声明宏一样(带 !),但底层是过程宏:
let users = sqlx::query!("SELECT * FROM users WHERE id = ?", id);sqlx::query! 是个函数式过程宏,它会在编译期连数据库验证 SQL 语法对不对、字段类型匹不匹配。这种"在编译期做你想象不到的事"是过程宏的拿手好戏。
跟 Java 注解处理器的对比
Java 的注解处理器(APT,annotation processing tool)是 Java 唯一接近"编译期生成代码"的机制。Lombok 的 @Data、MapStruct 的 mapper 生成、AutoValue 都是基于这个。
但跟 Rust 过程宏比,APT 有几个明显劣势:
- APT 只能加东西,不能改东西。你能让 Lombok 给 class 加 getter,但你没法让它修改已有方法。Rust 的属性宏可以完全替换掉一个函数。
- APT 是单独的处理阶段,IDE 支持差,常常需要插件配合(Lombok 在 IDE 里要装插件这事大家都很熟)。Rust 的过程宏跟编译器走同一条路,IDE 通过 rust-analyzer 直接看到展开后的代码,体验好得多。
- APT 没有过程宏里那种"函数式宏"调用形式。Java 里你只能
@SomeAnnotation,不能写someMacro!(...)这种调用。 - APT 的工具链相对简陋,写起来费劲。Rust 这边有
syn+quote+proc-macro2这一套成熟工具链,社区生态也很活跃。
不过 Rust 过程宏也有代价,最大的就是编译慢,syn 解析整个 Rust 语法树是个相当重的活。一个项目里 serde、tokio、sqlx 这套用起来,编译时间会肉眼可见地变长。
啥时候用宏
讲完宏的能力,最后给点实用建议:
- 优先用函数。能用函数解决的问题就别用宏。
- 想消除一些样板代码、需要可变参数,用声明宏。
- 想给 struct 派生 trait,用派生宏。社区有现成的就用社区的,自己写一个派生宏的成本不低。
- 想做"看起来很魔法"的事,比如编译期验证 SQL、注册路由、定义 DSL,要写函数式过程宏或属性宏。
写宏(特别是过程宏)属于 Rust 比较高级的话题,本文不会教大家怎么写一个过程宏,我自己看宏的代码也是两眼一抹黑,因为宏的实现代码可读性都是很差的。碰到一个宏的时候,知道它们是什么、大概在做什么,这就够了。
到这里 Rust 语言层面比较独立的几块特性我们就讲得差不多了。下一节我们换个角度,看一个 Java 程序员特别关心的话题:异步编程。我们会从 Future 的设计讲起,看看 tokio 这个事实标准的 runtime 是怎么用的,以及在多线程 async 环境下最容易踩的几个坑。
十七、异步编程:async/await 和 tokio
终于到异步编程这一节了。说实话,我个人觉得这一节是 Rust 里"概念-实践"差距最大的一块,基础语法 async 和 await 看起来简单得不行,但真要写起项目来,能在编译器面前少挨几顿打就算赢。
这一节我们站在 Java 开发者的视角来理解 Rust 的异步。如果一上来就直接讲 Future、Pin、Waker,效果不一定好,所以我们先把 Java 这边的几张牌过一遍,再对着 tokio 是怎么做的来看,思路会比较顺。
先回顾一下 Java 这边的姿势
我们写 Java 服务端的时候,"异步"这件事大致经历了几个阶段,常用姿势串一下。
第一个是 Java Thread。new 一个 Thread 就是一个真正的内核线程,跟 OS 线程一对一。线程切换、栈空间、上下文保存这些事 OS 全包了,代价就是线程不便宜,一台机器上能开的 Thread 数量是有限的。所以我们一般不会自己 new Thread,而是丢到线程池里。
第二个是线程池,最熟的姿势:
ExecutorService pool = Executors.newFixedThreadPool(8);
Future<String> f = pool.submit(() -> doSomething());
String result = f.get();线程池的本质就两个东西:
- 一组固定数量的 worker 线程,长期 alive,循环从队列里取任务执行
- 一个任务队列,submit 方法把任务塞到队列里
这个模型记在脑子里,下面看 tokio 你会发现几乎是一回事。
第三个是 CompletableFuture,写一组有依赖的异步任务:
CompletableFuture<String> fut = CompletableFuture.supplyAsync(() -> fetchUser(42))
.thenApply(user -> user.toUpperCase())
.thenAccept(System.out::println);这里有一个非常关键的点:supplyAsync 一调用,任务就提交到线程池开始跑了。CompletableFuture 是 eager 的。这一点先记心里,因为 Rust 的 Future 是惰性的。
第四个是虚拟线程。JDK 21 之后,我们可以 Thread.startVirtualThread(...),写出来还是同步代码长相,底层 N:M 调度,遇到阻塞 IO 自动让出。这是 Java 在异步领域的"答案"。如果你不了解虚拟线程,可以看我之前写的 《Java 虚拟线程》。
接下来,我们看看 Rust 世界里面异步是怎么玩的。
tokio 的线程模型:把 Java 线程池里的 Thread 换成 Future
先讲一个跟 Java 不太一样的地方:Rust 标准库里没有异步 runtime。
Java 这边 ForkJoinPool、Loom 的调度器都是 JDK 自带,但 Rust 走的是"语言提供 async 语法和 Future trait,runtime 留给社区"的路线。原因也好理解,Rust 要覆盖从嵌入式到服务端的各种场景,硬塞一个 runtime 进标准库,要么嵌入式的人不爽(太重),要么服务器端的人不爽(太弱)。
实际项目里,社区基本统一用 tokio。它对应的角色你可以理解为"Rust 异步世界的 Netty + ForkJoinPool"。其他还有 async-std、smol,但 tokio 是事实标准,公司里九成以上的 Rust 项目都在用它。
加 tokio 依赖:
[dependencies]
tokio = { version = "1.52.3", features = ["full"] }features = ["full"] 是开发期图省事的写法,实际项目你可能只开 ["rt-multi-thread", "macros", "net"] 等具体特性,能瘦身不少。这块先不展开。
接下来看 tokio 默认的多线程 runtime 是什么样的:
- 启动 N 个 worker 线程(默认是 CPU 核数),每个 worker 是一个 OS 线程
- 每个 worker 自己持有一个本地任务队列
- 还有一个全局任务队列
- worker 之间会做 work-stealing:自己的队列空了,会从其他 worker 那"偷"任务来执行
是不是很眼熟?这个结构跟 Java 的 ForkJoinPool 几乎一模一样。
但有一个非常关键的区别:
- Java 的
FixedThreadPool调度的是 Runnable/Callable,每个任务在 worker 上从头跑到尾,中间不让出 - tokio 调度的是 Future,每个任务可以执行到一半(碰到 await)让出,等条件好了再被唤醒接着跑
这就是 tokio 能做到"百万级并发"的关键:worker 还是只有那几个,但任务(Future)是非常轻量的对象,一个 worker 可以来回切换跑几千个 Future。这跟 Java 虚拟线程的思路是一致的,只是 Java 把这套切换机制做进了 JVM/JDK,Rust 把它做进了语言(async/await)加上用户态库(tokio)。
把这个记在心里,下面所有 tokio 的 API 都是围绕"怎么把 Future 喂给这个调度器"在转。
Rust 的 Future:惰性的"任务对象"
铺垫完调度器,我们来看任务本身。Rust 的异步任务叫 Future,对应 Java 里的 CompletableFuture<T>。但有一个非常关键的差异:Rust 的 Future 是惰性的(lazy)。
什么意思?我们看代码:
async fn fetch_user(id: u64) -> String {
println!("正在 fetch user {}", id);
// 假装做了点事
format!("user-{}", id)
}
#[tokio::main]
async fn main() {
let fut = fetch_user(42); // 注意,这一行其实啥也没干
println!("Future 已创建,但还没开始执行");
let user = fut.await; // 到这里 Future 才真正开始跑
println!("拿到 {}", user);
}输出:
Future 已创建,但还没开始执行
正在 fetch user 42
拿到 user-42看到了吧?调用 async fn 不会真的执行函数体,只是返回了一个 Future 对象,可以理解为打包了一个"待执行的任务"。直到你 .await 它(或者把它交给 runtime 去 poll),它才真正开始跑。
对比 Java 的 CompletableFuture:
CompletableFuture<String> fut = fetchUser(42); // 任务这一刻就提交到线程池了
fut.join(); // 这里只是在等结果这是一个非常重要的心智差异,记心里:Rust 的 async fn 调用约等于"创建一个任务对象",.await 才是"驱动它跑"。
那 Future 内部到底长啥样?我们不打算扒到 Pin、Waker 那么深,了解一个事实就够了:编译器会把 async 块编译成一个状态机 struct,每次被 poll 推进一步,碰到 await 就把状态保存好返回,等条件满足再被叫起来继续跑。这个事实后面讲 Send 的时候有用。
#[tokio::main]:把 main 函数变成异步入口
Rust 的 main 函数必须是同步的,但我们想在里面写 async 代码怎么办?tokio 提供了一个属性宏:
#[tokio::main]
async fn main() {
println!("hello async world");
}这个宏背后展开成什么呢?大概是这样:
fn main() {
let rt = tokio::runtime::Runtime::new().unwrap();
rt.block_on(async {
println!("hello async world");
});
}也就是说,它给你创建了一个 tokio runtime(前面说的那个 worker 线程池就是这时候起来的),然后用 block_on 阻塞地等你的 async 块跑完。block_on 这个方法你也可以手动用,比如在测试或者跟同步代码混用的场景。
spawn / join! / select!:往调度器里喂 Future
接下来看几个最常用的 API。我们对着 Java 的 executor.submit / allOf / anyOf 看,会发现一一对应。
tokio::spawn:对应 Java 的 executor.submit
把一个 Future 交给 runtime 去调度,立刻拿到一个 JoinHandle。这个 handle 跟 Java 的 Future 概念上是一回事,await 它能拿到任务的结果:
use tokio::time::{sleep, Duration};
async fn task(name: &str, secs: u64) {
println!("{} 开始", name);
sleep(Duration::from_secs(secs)).await;
println!("{} 结束", name);
}
#[tokio::main]
async fn main() {
let h1 = tokio::spawn(task("A", 1)); // 立刻提交到 runtime
let h2 = tokio::spawn(task("B", 2));
h1.await.unwrap();
h2.await.unwrap();
}spawn 出去的任务有可能跑在调度器的任意一个 worker 线程上,所以它要求 Future 是 Send 的。Send 是啥下一节专门讲。
tokio::join!:等若干 Future 全部完成
类似 CompletableFuture.allOf(...).join(),但有个区别:join! 不会把 Future 提交到调度器,而是在当前任务里并发推进它们:
#[tokio::main]
async fn main() {
// 串行版本:A 跑完再跑 B,总共 3 秒
task("A", 1).await;
task("B", 2).await;
// 并发版本:A B 同时跑,总共 2 秒
tokio::join!(task("A", 1), task("B", 2));
}注意"并发地"不一定是"并行地"。join! 的几个 Future 都在同一个任务里,谁 await 阻塞了就让别的接着跑,整体还是单线程的逻辑。所以 join! 不要求 Send。
什么时候用 spawn、什么时候用 join!?
- 想"独立调度、可能跨线程并行执行"用
spawn - 想"在当前任务里并发推进、不要求 Send"用
join!
tokio::select!:等多个 Future 中先到的那个
类似 CompletableFuture.anyOf(...):
#[tokio::main]
async fn main() {
tokio::select! {
_ = sleep(Duration::from_secs(1)) => {
println!("超时了");
}
result = fetch_user(42) => {
println!("拿到 {}", result);
}
}
}这个非常常用,最典型的几个场景是给 IO 加超时、监听 ctrl-c 退出信号、从多个 channel 里抢消息等等。
select! 有个坑:没有被选中的那个 Future 会被直接丢弃。所以如果你的 Future 不是"取消安全"的(cancel-safe),可能丢了之后状态就乱了。一般标准库和 tokio 自己的 API 都会标注哪些是 cancel-safe,这里先不展开,碰到了再说。
Send 和 Sync:把"线程安全"做进类型系统
下面这一节单独拎出来讲,因为它在 Rust 异步里是绕不过的一块,但是它属于比较复杂的话题了,对于初学者来说,大概知道怎么回事就行了。理解了它,前面 spawn 为啥要 Send,还有后面碰到的各种 "xxx is not Send/Sync" 报错,会清晰很多。
我们先看一下 Java 这边的处境。写 Java 的时候,"这个类型能不能跨线程用"这件事是没有写进类型系统的。ArrayList 不是线程安全的、ConcurrentHashMap 是线程安全的,但这件事编译器根本不知道,你把 ArrayList 共享到多个线程里去用,编译能过、运行也不会立刻报错,只是数据可能就乱了。我们靠的是 Javadoc、靠经验、靠出过事的项目才知道哪个能用哪个不能用。
Rust 的思路完全不一样:把"能不能跨线程"做成两个 marker trait,让编译器替我们检查。这就是 Send 和 Sync。先记一句话总结:
- Send:一个值能不能"移动到另一个线程",重点是所有权转移
- Sync:一个值能不能"被多个线程共享引用",重点是共享引用
Send:能否把所有权"移动"到另一个线程
如果一个类型 T 是 Send,意思是把 T 的值的所有权从一个线程交给另一个线程是安全的。绝大部分类型都是 Send:i32、String、Vec<T>(要求 T: Send)、自己写的普通 struct 这些默认都是。
例外有几个:
Rc<T>:引用计数没用原子操作,跨线程并发改计数会竞争,所以不是 SendMutexGuard<'_, T>:std 的 Mutex 是 OS 线程级的锁,guard 必须在加锁那个线程释放,所以不是 Send- 裸指针
*const T/*mut T:编译器对它一无所知,不敢替你做保证
它们都有对应的"可跨线程版本":Arc<T> 用原子计数,是 Send;tokio 自带的 tokio::sync::MutexGuard 也是 Send 的。
Sync:能否被多个线程"共享引用"
定义稍微绕一点:如果 &T 是 Send,那么 T 就是 Sync。换句话说,T 是 Sync 意味着多个线程同时持有 &T 是安全的。举几个例子:
i32、String、Vec<T>(要求 T: Sync)这些都是 SyncMutex<T>(要求 T: Send)是 Sync,这正是它存在的意义,让 T 能被多个线程共享 + 修改RefCell<T>不是 Sync。它的借用检查是单线程的,多线程共享&RefCell然后并发借用,根本不安全Cell<T>也不是 Sync,原因类似
我们之前在智能指针那一节就总结过一个经验法则,现在把它跟 Send/Sync 对上号了:
- 单线程下要"共享 + 内部可变":
Rc<RefCell<T>> - 多线程下要"共享 + 内部可变":
Arc<Mutex<T>>或Arc<RwLock<T>>
自动派生
Send 和 Sync 都是 auto trait,编译器会根据字段自动派生。规则非常简单:所有字段都 Send,自己才 Send;只要有一个字段不是 Send,自己就不是。Sync 同理。
所以绝大部分时候你不用主动想这件事,只有当 struct 里夹了 Rc、RefCell、裸指针这种"特殊成员"时,类型才会莫名其妙不是 Send/Sync,顺着字段找原因就行。
极少数情况下你需要手动给类型打上 Send/Sync 标记(比如自己用裸指针实现了一个能保证并发安全的数据结构),这时候要写 unsafe impl Send for MyType {}。这个 unsafe 是在说:编译器没法替你检查了,出了问题你自己负责。新手碰到的概率很低,留个印象就行。
把 Send 套回 spawn:std Mutex 的经典坑
铺垫完 Send 和 Sync,我们再回头看 tokio::spawn 的签名(简化版):
pub fn spawn<F>(future: F) -> JoinHandle<F::Output>
where
F: Future + Send + 'static,
F::Output: Send + 'static,为啥要求 Future 是 Send,前面已经说过,多线程 runtime 下任务可能在不同 worker 线程之间移动。真正的问题是:什么样的 async 块会被编译成 Send 的 Future?
前面我们讲 Future 内部时提过,编译器会把 async 块编译成一个状态机 struct,所有跨 await 还活着的局部变量都会成为这个 struct 的字段。再叠加 Send 的派生规则(所有字段都 Send,整个 struct 才 Send),判断标准就出来了:跨 await 持有的变量是不是全都是 Send。
最经典的反例就是 std Mutex 的 guard:
use std::sync::Mutex;
#[tokio::main]
async fn main() {
let m = Mutex::new(0);
tokio::spawn(async move { // 编译错误就报在这一行:future is not `Send`
let mut guard = m.lock().unwrap();
*guard += 1;
do_something_async().await; // guard 跨过了这个 .await,没机会被 drop
// guard 一直活到这里才 drop
});
}编译器会告诉你 MutexGuard 不是 Send,所以这个 async 块也不是 Send,所以不能 spawn。两个解法:
办法一,缩短 guard 的存活范围,不要让它跨 await:
{
let mut guard = m.lock().unwrap();
*guard += 1;
} // guard 在这里就 drop 了
do_something_async().await;办法二,用 tokio::sync::Mutex,这是个异步锁,它的 guard 是 Send 的:
use tokio::sync::Mutex;
let m = Mutex::new(0);
let mut guard = m.lock().await; // 注意是 .await,不是 .unwrap()
*guard += 1;
do_something_async().await; // OK实践经验:能用办法一就用办法一。因为 tokio 的 Mutex 比 std 的贵,能不用就别用。
顺便说一下:为什么有了 Send 还要 Sync?
讲到这里可能有读者会冒出一个疑问:Send 已经管了"跨线程"这件事,为啥还要再搞一个 Sync?两个 trait 听起来挺像,合并成一个不行吗?
关键就在 &T 上。
对绝大多数类型,&T 确实就是"只读"。这种情况下"独占 T"和"共享 &T"在安全性上没区别,Send 一个 trait 就够了。但 Rust 里有一类很特别的"内部可变"类型,最典型的就是 Cell<T>:
use std::cell::Cell;
let c: Cell<i32> = Cell::new(0);
let r: &Cell<i32> = &c;
r.set(42); // 拿着 &Cell 就能改值&Cell 看起来是不可变引用,但实际上能通过它修改内部的值,这就是所谓的"内部可变性"。这下 Send 和 Sync 就分了家:
Cell<T>是 Send 吗?是的。整个 Cell 搬到另一个线程是安全的,因为同一时刻只有一个线程拥有它Cell<T>是 Sync 吗?不是。两个线程同时拿着&Cell<i32>、都调.set(...),Cell 内部没做任何同步,data race 直接发生
Send 通过、Sync 不通过,这就是 Sync 必须独立存在的意义。如果 Rust 里所有 &T 都意味着"只读",Sync 确实就是冗余的;偏偏因为有 Cell、RefCell、UnsafeCell 这种"&T 也能改"的设计,"共享引用是否安全"必须单独检查一次。
反过来看 Mutex<T> 你也会更清楚 Sync 的价值。Mutex<T> 是 Sync 的,因为内部本来就有锁,多个线程并发拿着 &Mutex<T> 调 .lock() 是安全的,锁会序列化它们。Mutex 存在的意义就是把一个"非 Sync"的 T 包起来,让它可以被并发共享。
阻塞操作:不要污染 runtime
这是另一个非常容易踩的坑,Java 那边其实也有完全对应的问题。看这个代码:
async fn bad() {
std::thread::sleep(Duration::from_secs(5)); // 错!
// 同步的文件读、阻塞的 HTTP 库、CPU 密集的计算,都不该这么用
}为啥不行?回到我们最开始说的那个调度器结构:tokio 的 worker 线程数量是有限的(默认是 CPU 核数)。你这 5 秒的同步 sleep 把一个 worker 占着不动,整个 runtime 上跑的其他任务都受影响。这跟在 Netty 的 EventLoop 上写阻塞代码是一个性质的错误。如果你之前看过我写的 Java 虚拟线程那篇文章,应该一下子就 get 到了。
正确的做法是:
- 有异步版本就用异步版本:
tokio::time::sleep、tokio::fs、reqwest等 - 实在要跑同步代码:用
tokio::task::spawn_blocking
let result = tokio::task::spawn_blocking(|| {
// 这里跑同步代码,会被丢到一个专门的"阻塞线程池"
expensive_sync_computation()
}).await.unwrap();spawn_blocking 维护一个独立的线程池(默认 512 个线程),专门给你跑那些"不得不阻塞"的代码。它跟 worker 线程池是分开的,所以不会互相影响。Java 这边类似的姿势是给阻塞任务单独配一个线程池,思路一致。
Channel:异步任务之间的通信
跟 Java 里 BlockingQueue 类似,tokio 提供了几种 channel。最常用的是 mpsc(多生产者单消费者):
use tokio::sync::mpsc;
#[tokio::main]
async fn main() {
let (tx, mut rx) = mpsc::channel(32); // 缓冲区大小 32
// 生产者
tokio::spawn(async move {
for i in 0..5 {
tx.send(i).await.unwrap();
}
// tx 在这里 drop,rx.recv() 之后会收到 None
});
// 消费者
while let Some(value) = rx.recv().await {
println!("收到 {}", value);
}
}发送和接收都是 async 的,缓冲区满了会让出,缓冲区空了也会让出。
tokio 还有 oneshot(一次性传一个值,常用于"任务完成的通知")、broadcast(多消费者,每个消费者都能收到全部消息)、watch(适合配置热更新这种场景),按需选用。
异步小结
异步这块涉及的东西不少,我们用几个要点串一下:
- tokio 多线程 runtime 跟 Java 的
ForkJoinPool结构很像:N 个 worker 线程 + 本地队列 + work-stealing。区别在于 tokio 调度的是 Future(很轻量、可让出),Java 线程池调度的是从头跑到尾的 Runnable - Rust 的 Future 是惰性的,调用 async fn 不等于开始执行,必须
.await或者交给 runtime 去 poll;而 Java 的 CompletableFuture 是 eager 的 - Rust 标准库不带 runtime,事实标准是 tokio,入口一般用
#[tokio::main] - 想"独立调度、可能跨线程并行"用
tokio::spawn(对应executor.submit);想"并发等多个" 用tokio::join!(类似allOf);想"等先到的"用tokio::select!(类似anyOf) - Send 和 Sync 这两个 marker trait 把"线程安全"做进了类型系统,弥补了 Java 这边只能靠 Javadoc 的不足。Send 表示"可跨线程转移所有权",Sync 表示"可跨线程共享引用"
- 多线程 runtime 下 spawn 要求 Future 是 Send,最常见的报错就是 std Mutex 的 guard 跨 await
- 不要在 async 里调用阻塞 API,类比 Netty EventLoop 上写阻塞代码;非要做同步重活,用
spawn_blocking - 任务间通信用 tokio 的 channel,最常用的是
mpsc,按场景还有oneshot、broadcast、watch
十八、错误处理实践:anyhow 和 thiserror
前面 Result 那一节我们已经知道了 Rust 错误处理的基本面:用 Result<T, E> 表达一个可能失败的操作,用 ? 操作符做早返回。
但真要写一个像样的项目,光靠标准库提供的这些其实是不够的。我们看一个非常常见的小例子:一个函数里要先读文件,再把文件里的字符串 parse 成数字。
这两步会失败的方式是不一样的:
- 读文件失败:
std::io::Error - parse 失败:
std::num::ParseIntError
fn read_number(path: &str) -> Result<i32, ???> {
let content = std::fs::read_to_string(path)?; // 这里会抛 std::io::Error
let n: i32 = content.trim().parse()?; // 这里会抛 ParseIntError
Ok(n)
}??? 这一格写啥?两个错误类型完全不一样,但函数的返回类型只能写一个。
这就是社区里 anyhow 和 thiserror 这两个库要解决的问题。简单说,思路有两种:
- 应用代码(写 main、写业务逻辑):用 anyhow,把所有错误统一包成一个万能错误类型,怎么爽怎么来。
- 库代码(要发布出去给别人用的):用 thiserror,定义清晰、结构化的错误枚举,让使用方能区分不同的失败原因。
类比 Java 的话,anyhow 就像直接 throw 一个 RuntimeException,把原因塞进 message 和 cause;thiserror 就像写一组语义清晰的 checked exception,让调用方能 catch 到具体的子类。
我们分别看看。
thiserror:定义结构化的错误类型
thiserror 是一个过程宏库,用 derive 自动给你生成 std::error::Error 这个 trait 的实现。
回到上面那个例子:
use thiserror::Error;
#[derive(Error, Debug)]
pub enum ReadNumberError {
// 文件读不出来
#[error("读文件失败: {0}")]
Io(#[from] std::io::Error),
// 解析数字失败
#[error("解析数字失败: {0}")]
Parse(#[from] std::num::ParseIntError),
}
pub fn read_number(path: &str) -> Result<i32, ReadNumberError> {
let content = std::fs::read_to_string(path)?; // io::Error 自动转成 ReadNumberError::Io
let n: i32 = content.trim().parse()?; // ParseIntError 自动转成 ReadNumberError::Parse
Ok(n)
}我们看几个关键点:
#[derive(Error, Debug)]:thiserror 帮我们实现std::error::Error,Debug是标准库自带的。#[error("...")]:定义错误的Display实现,也就是错误信息怎么打印。#[from]:这个是最关键的。它会生成一个From<std::io::Error> for ReadNumberError的实现。有了From,?操作符就会自动帮我们做转换。
调用方拿到 ReadNumberError 之后,可以 match 它的具体变体来做不同的处理:
match read_number("config.txt") {
Ok(n) => println!("拿到 {}", n),
Err(ReadNumberError::Io(_)) => eprintln!("文件没找到,用默认值"),
Err(ReadNumberError::Parse(_)) => eprintln!("文件内容格式不对"),
}这就是结构化的好处,错误的类型本身就承载了语义。库的作者把错误枚举设计好,使用方就能优雅地处理不同的失败场景。
类比 Java,thiserror 大致相当于:
public class ReadNumberException extends Exception {
public static class Io extends ReadNumberException { ... }
public static class Parse extends ReadNumberException { ... }
}只不过 Rust 这边用的是 enum,而且 thiserror 把模板代码(错误信息、cause 链、From 转换)全给你生成了,省心很多。
anyhow:应用代码的省心包
anyhow 走的是另一条路。它对外只暴露一个类型:anyhow::Error,可以包住任何实现了 std::error::Error + Send + Sync + 'static 的错误。
我们再写一遍那个例子:
use anyhow::Result; // 等价于 Result<T, anyhow::Error>
fn read_number(path: &str) -> Result<i32> {
let content = std::fs::read_to_string(path)?;
let n: i32 = content.trim().parse()?;
Ok(n)
}代码瞬间清爽。注意几个点:
anyhow::Result<T>是Result<T, anyhow::Error>的别名。- 任何实现了标准
Errortrait 的错误,?都能自动转成anyhow::Error,我们不用自己写From。 - main 函数也可以用:
fn main() -> anyhow::Result<()> {
let n = read_number("config.txt")?;
println!("拿到 {}", n);
Ok(())
}anyhow 还有一个特别实用的功能,叫 .context(),可以给错误链上加一层信息:
use anyhow::{Context, Result};
fn load_config(path: &str) -> Result<Config> {
let content = std::fs::read_to_string(path)
.with_context(|| format!("读配置文件失败: {}", path))?;
let config: Config = serde_json::from_str(&content)
.with_context(|| "解析 JSON 失败")?;
Ok(config)
}最终如果失败,打印出来的错误是这样的:
Error: 解析 JSON 失败
Caused by:
0: 读配置文件失败: /etc/myapp/config.json
1: No such file or directory (os error 2)这个 context 链就像 Java 里的 Exception.getCause() 一样,把错误传递的路径完整保留下来,debug 的时候非常好用。
啥时候用哪个
这个问题社区里讨论了很多次,常用的标准是:
- 写应用、写工具、写 main:用 anyhow。一个类型搞定一切,代码简洁,错误信息友好。反正最终错误就是给人看的(打日志、退出码、用户提示),结构化没意义。
- 写库(要发布给别人用的 crate):用 thiserror。库的使用者需要根据错误类型做不同的逻辑分支,你要是给人扔一个
anyhow::Error,别人没法 match,只能拿到一段字符串。
混用其实也很常见,也是我个人比较推荐的做法:库内部用 thiserror 暴露规整的错误枚举,应用代码用 anyhow 把这些错误聚合在一起处理。
最后再说几条实践经验:
- 库代码里不要 panic(除非真的是 bug 兜底),把错误一律用 Result 暴露给调用方
- 应用的 main 直接写成
fn main() -> anyhow::Result<()>,让 anyhow 帮我们打印错误链,省掉自己写eprintln! - 调试不顺利的时候,加
RUST_BACKTRACE=1跑一下,anyhow 会顺手把 backtrace 一起打出来
到这里我们基本就把日常错误处理摸熟了。最后一节我们看看 Rust 生态里几个绕不开的库。
十九、常用 crate 生态一览
写 Java 项目,光会语法是不够的,还得知道 Jackson、Guava、SLF4J、Spring 这些标配。Rust 这边也是一样,社区里有几个事实上的必装件。
这一节就是清单式地过一下这些 crate,每个简单介绍 + 跟 Java 对比,让你后面真要动手写项目的时候心里有谱。具体的细节我都不展开,每个 crate 的官方文档都写得很好,到时候去翻就行。
serde:对应 Jackson
序列化反序列化的事实标准,地位相当于 Java 的 Jackson。
serde 本身只是个框架,定义了 Serialize 和 Deserialize 这两个 trait,至于具体跟哪种格式打交道(JSON、YAML、TOML、bincode、MessagePack),由配套的 crate 决定。最常用的是 serde_json。
[dependencies]
serde = { version = "1", features = ["derive"] }
serde_json = "1"use serde::{Serialize, Deserialize};
#[derive(Serialize, Deserialize, Debug)]
struct User {
id: u64,
name: String,
#[serde(default)] // 反序列化时,字段缺失就用 Default::default()
active: bool,
}
fn main() -> anyhow::Result<()> {
let json = r#"{"id": 1, "name": "alice"}"#;
let user: User = serde_json::from_str(json)?;
println!("{:?}", user); // User { id: 1, name: "alice", active: false }
let s = serde_json::to_string(&user)?;
println!("{}", s);
Ok(())
}跟 Java Jackson 对比着看:
#[derive(Serialize, Deserialize)]对应 Jackson 的注解(@JsonProperty之类的)。#[serde(rename = "user_id")]、#[serde(default)]、#[serde(skip)]这些跟 Jackson 注解一一对应。- serde 在编译期生成代码,Jackson 主要靠反射,所以 serde 的性能更好,代价是报错信息会稍微绕一些。
我个人感觉 serde 是 Rust 里最让我惊艳的库之一,它把"用 derive 生成代码"这件事玩到了极致。
reqwest:对应 OkHttp / HttpClient
HTTP 客户端的事实标准。底层基于 hyper,对外提供同步和异步两套 API。
[dependencies]
reqwest = { version = "0.12", features = ["json"] }
tokio = { version = "1", features = ["full"] }#[tokio::main]
async fn main() -> anyhow::Result<()> {
let resp: serde_json::Value = reqwest::get("https://httpbin.org/get")
.await?
.json()
.await?;
println!("{:#?}", resp);
Ok(())
}对比 Java:
- 同步用法跟 OkHttp 思路一样:构造请求、send、拿 response。
- 异步用法跟 Java 11 引入的
HttpClient异步 API 类似,但 Rust 这边是真正的 async/await,没有CompletableFuture链式调用那一坨。 - 配合 serde,
.json::<T>()直接把 body 反序列化成 struct,比 Java 那边写objectMapper.readValue(body, User.class)还顺。
顺便提两个相关的搭档:想做 HTTP server,用 axum 或 actix-web(对应 Spring Web / Vert.x);想做 gRPC,用 tonic(对应 grpc-java)。
tracing:对应 SLF4J + Logback
日志和 telemetry 的事实标准。注意 tracing 不只是日志库,它的设计目标是结构化的可观测性,包含了 log、span(链路)、event。简单理解,tracing 一个就替代了 SLF4J + Logback + 部分 OpenTelemetry 的角色。
跟 SLF4J 一样,tracing 本身只是一套 facade,真正把日志写出去的是 subscriber:
[dependencies]
tracing = "0.1"
tracing-subscriber = "0.3"use tracing::{info, warn, instrument};
#[instrument] // 给函数自动加 span,进入退出都会有日志,参数也会自动打出来
fn handle_request(user_id: u64) {
info!(user_id, "开始处理请求");
if user_id == 0 {
warn!("user_id 为 0,可能是异常请求");
}
info!("处理完成");
}
fn main() {
tracing_subscriber::fmt::init(); // 最简单的 subscriber,把日志打到 stderr
handle_request(42);
}输出大致是:
2026-05-07T08:00:00Z INFO handle_request{user_id=42}: myapp: 开始处理请求 user_id=42
2026-05-07T08:00:00Z INFO handle_request{user_id=42}: myapp: 处理完成注意输出里的 handle_request{user_id=42} 这一段,这是 tracing 自动带上的 span 信息,整个请求的调用链一眼就能串起来。
类比 Java:
info!/warn!/error!这套宏,对应 SLF4J 的log.info(...)。#[instrument]对应 Spring AOP + 切面打日志的那种效果。- subscriber 的替换,对应 Logback 配置 appender。
- 结合
tracing-opentelemetry,可以把 span 直接打到 Jaeger / Tempo / Datadog,对应 Java 那边的 micrometer-tracing。
如果你只是想要简单的"打日志",社区还有一个更轻量的选择叫 log + env_logger,跟 SLF4J 的简单使用类似。但我建议直接上 tracing,未来有 telemetry 需求的时候可以平滑接上。
sqlx / sea-orm:对应 MyBatis 和 JPA
数据库这块 Rust 没有像 Java 那样大一统的方案。社区里目前的两个主流:
- sqlx:偏 SQL-first,跟 Java 的 MyBatis、JdbcTemplate 类似。你自己写 SQL,sqlx 提供异步执行、参数绑定、结果映射。最大的特色是编译期检查 SQL,用
sqlx::query!宏写的 SQL,会在编译时连到一个真实的数据库做语法和字段校验。 - sea-orm:偏 ORM,跟 Java 的 JPA / Hibernate 类似。提供实体定义、查询构建器、关系映射,让你少写 SQL。
我们各看一段示例。
sqlx 风格(自己写 SQL):
use sqlx::PgPool;
#[derive(sqlx::FromRow)]
struct User {
id: i64,
name: String,
}
async fn find_user(pool: &PgPool, id: i64) -> anyhow::Result<Option<User>> {
let user = sqlx::query_as::<_, User>("SELECT id, name FROM users WHERE id = $1")
.bind(id)
.fetch_optional(pool)
.await?;
Ok(user)
}写起来其实跟 Spring 里用 Mybatis 差不多,SQL 自己写,结果映射到 struct。
sea-orm 风格(ORM):
use sea_orm::*;
let user: Option<user::Model> = User::find_by_id(1)
.one(&db)
.await?;跟 JPA 的 userRepository.findById(1) 几乎一对一对应。
怎么选?我个人的经验是:
- 项目以业务逻辑为主、SQL 不复杂的,sea-orm 上手快、心智负担小。
- 性能敏感、SQL 比较定制化、或者团队 SQL 功底好的,sqlx 更合适,编译期校验 SQL 是个非常香的特性。
- 真不知道选哪个,从 sqlx 开始。它更轻量,万一以后想换 ORM 也好换。
其他值得知道的几个
按使用频率从高到低简单列一下,篇幅有限就不展开了:
- axum:最主流的 HTTP server 框架,对应 Spring Web。
- tokio-util / futures:异步工具集,比 tokio 自带的更全。
- rayon:数据并行(多核 CPU 跑并行迭代器),对应 Java 的 parallel stream,但更扎实。
- chrono / time:日期时间库,对应 Java 8+ 的 java.time。
- uuid:生成 UUID。
- regex:正则。
- once_cell / lazy_static:全局单例和懒加载,新版本里
std::sync::OnceLock已经原生支持。 - criterion:性能基准测试,对应 Java 的 JMH。
碰到一个新需求,习惯性去 crates.io 搜一下,基本都能找到对应的库。社区生态这几年发展非常快,体验已经接近 Java、Python 这些老牌生态了。
总结
到这里,写一个像样的 Rust 项目所需要的基本面我们就过完了:语言、异步、错误处理、生态。剩下的就是去写代码、去翻文档、去跟编译器斗智斗勇。
最后一句老生常谈:Rust 学起来确实苦,学习曲线异常陡峭,但它逼着你把很多 Java 里"先跑起来再说"的问题想清楚,长远看对写代码的功力是有帮助的。希望本文能给你一个相对平滑的起手姿势,剩下的就交给时间了。
(全文完)
0 条评论